What is possible and not possible during the Nativity Fast?
In 2018, the Nativity Fast will begin on November 28. During this period, Orthodox believers prepare to celebrate Christmas...
Leading scientific journal Nature reported the discovery of a second genetic code - a kind of "code within a code" that was recently cracked by molecular biologists and computer programmers. Moreover, in order to identify it, they did not use evolutionary theory, but information technology.
The new code is called the Splicing Code. It is located inside DNA. This code controls the underlying genetic code in a very complex yet predictable manner. The splicing code controls how and when genes and regulatory elements are assembled. Unraveling this code within a code helps shed light on some of the long-standing mysteries of genetics that have surfaced since the Human Genome Sequencing Project. One of these mysteries was why in such a complex organism as the human there are only 20,000 genes? (Scientists expected to find much more.) Why are genes broken up into segments (exons), which are separated by noncoding elements (introns), and then joined together (that is, spliced) after transcription? And why do genes turn on in some cells and tissues, but not others? For two decades, molecular biologists have been trying to elucidate the mechanisms of genetic regulation. This article makes a very important point in understanding what is really going on. It doesn't answer all the questions, but it does demonstrate that the internal code exists. This code is a system of information transmission that can be deciphered so clearly that scientists could predict how the genome might behave in certain situations and with inexplicable precision.
Imagine that you hear an orchestra in the next room. You open the door, look inside and see three or four musicians playing musical instruments in the room. This is what Brandon Frey, who helped break the code, says the human genome looks like. He says: “We could only detect 20,000 genes, but we knew they made up a huge number of protein products and regulatory elements. How? One method is called alternative splicing.". Different exons (parts of genes) can be assembled in different ways. “For example, three genes for the protein neurexin can create more than 3,000 genetic messages that help control the brain’s wiring.”, says Frey. The article also says that scientists know that 95% of our genes are alternatively spliced, and in most cases, transcripts (RNA molecules formed as a result of transcription) are expressed differently in different types of cells and tissues. There must be something that controls how these thousands of combinations are assembled and expressed. This is the task of the Splicing Code.
Readers who want a quick overview of the discovery can read the article at Science Daily entitled "Researchers Who Cracked the 'Splicing Code' Uncover the Mystery Behind Biological Complexity". The article says: “Scientists at the University of Toronto have gained fundamental new insights into how living cells use a limited number of genes to form incredibly complex organs like the brain.”. Nature itself begins with an article by Heidi Ledford, “Code Within Code.” This was followed by a paper by Tejedor and Valcárcel entitled “Gene Regulation: Cracking the Second Genetic Code. Finally, the clincher was a paper by a team of researchers from the University of Toronto led by Benjamin D. Blencowe and Brandon D. Frey, “Cracking the Splicing Code.”
This article is a victory for information science that reminds us of the codebreakers of World War II. Their methods included algebra, geometry, probability theory, vector calculus, information theory, program code optimization, and other advanced techniques. What they didn't need was evolutionary theory, which has never been mentioned in scientific articles. Reading this article, you can see how much stress the authors of this overture are under:
“We describe a 'splicing code' scheme that uses combinations of hundreds of RNA properties to predict tissue-specific changes in the alternative splicing of thousands of exons. The code establishes new classes of splicing patterns, recognizes different regulatory programs in different tissues, and establishes mutation-controlled regulatory sequences. We have uncovered widespread regulatory strategies, including: the use of unexpectedly large property pools; identification of low levels of exon inclusion that are attenuated by the properties of specific tissues; the manifestation of properties in introns is deeper than previously thought; and modulation of splice variant levels by structural characteristics of the transcript. The code helped identify a class of exons whose inclusion silences expression in adult tissues by activating mRNA degradation, and whose exclusion promotes expression during embryogenesis. The code facilitates the discovery and detailed characterization of regulated alternative splicing events on a genome-wide scale.”
The team that cracked the code included specialists from the Department of Electronic and Computer Engineering, as well as from the Department of Molecular Genetics. (Frey himself works for a division of Microsoft Corporation, Microsoft Research) Like the codebreakers of yesteryear, Frey and Barash developed "a new method of computer-assisted biological analysis that detects 'code words' hidden within the genome". Using massive amounts of data generated by molecular geneticists, a team of researchers reverse-engineered the splicing code until they could not predict how he would act. Once the researchers had that figured out, they tested the code against mutations and saw how exons were inserted or deleted. They found that the code could even cause tissue-specific changes or act differently depending on whether the mouse was an adult or an embryo. One gene, Xpo4, is associated with cancer; The researchers noted: “These data support the conclusion that Xpo4 gene expression must be strictly controlled to avoid possible deleterious consequences, including tumorigenesis (cancer), since it is active during embryogenesis but is reduced in abundance in adult tissues. It turns out that they were absolutely surprised by the level of control they saw. Intentionally or not, Frey used the language of intelligent design rather than random variation and selection as a clue. He noted: “Understanding a complex biological system is like understanding a complex electronic circuit.”
Heidi Ledford said that the apparent simplicity of the Watson-Crick genetic code, with its four bases, triplet codons, 20 amino acids and 64 DNA "characters" - hides a whole world of complexity underneath. Enclosed within this simpler code, the splicing code is much more complex.
But between DNA and proteins lies RNA, a world of complexity all its own. RNA is a transformer that sometimes carries genetic messages and sometimes controls them, involving many structures that can influence its function. In a paper published in the same issue, a team of researchers led by Benjamin D. Blencowe and Brandon D. Frey from the University of Toronto in Ontario, Canada, report efforts to unravel a second genetic code that can predict how segments of messenger RNA transcribed from a specific gene, can mix and match to form a variety of products in different tissues. This process is known as alternative splicing. This time there is no simple table - instead there are algorithms that combine more than 200 different properties of DNA with determinations of RNA structure.
The work of these researchers points to the rapid progress that computational methods have made in assembling a model of RNA. In addition to understanding alternative splicing, computer science helps scientists predict RNA structures and identify small regulatory pieces of RNA that do not code for proteins. "It's a wonderful time", says Christopher Berg, a computational biologist at the Massachusetts Institute of Technology in Cambridge. “We will have great success in the future”.
Computer science, computational biology, algorithms and codes—these concepts were not part of Darwin's vocabulary when he developed his theory. Mendel had a very simplified model of how traits are distributed during inheritance. Additionally, the idea that features are encoded was only introduced in 1953. We see that the original genetic code is regulated by an even more complex code included within it. These are revolutionary ideas. Moreover, there are all signs that this level of control is not the last. Ledford reminds us that RNA and proteins, for example, have a three-dimensional structure. The functions of molecules can change when their shape changes. There must be something that controls the folding so that the three-dimensional structure does what the function requires. In addition, access to genes appears to be controlled another code, histone code. This code is encoded by molecular markers or “tails” on histone proteins that serve as centers for DNA twisting and supercoiling. Describing our times, Ledford talks about "continuous renaissance in RNA informatics".
Tejedor and Valcárcel agree that complexity lies behind the simplicity. “The concept is very simple: DNA makes RNA, which then makes protein.”, - they begin their article. “But in reality everything is much more complicated”. In the 1950s, we learned that all living organisms, from bacteria to humans, have a basic genetic code. But we soon realized that complex organisms (eukaryotes) have some unnatural and difficult to understand property: their genomes have peculiar sections, introns, that must be removed so that the exons can join together. Why? Today the fog is clearing: “The main advantage of this mechanism is that it allows different cells to choose alternative ways of splicing the precursor messenger RNA (pre-mRNA) and thus produce different messages from the same gene,”- they explain, - "and then different mRNAs can encode different proteins with different functions". You get more information out of less code, provided there is this other code inside the code that knows how to do it.
What makes breaking the splicing code so difficult is that the factors that control exon assembly are set by many other factors: sequences located near exon boundaries, intron sequences, and regulatory factors that either help or inhibit the splicing machinery. Besides, “the effects of a particular sequence or factor may vary depending on its location relative to intron-exon boundaries or other regulatory motifs”, Tejedor and Valcárcel explain. “Therefore, the greatest challenge in predicting tissue-specific splicing is calculating the algebra of the myriad motifs and the relationships among the regulatory factors that recognize them.”.
To solve this problem, a team of researchers fed a huge amount of data into a computer about RNA sequences and the conditions under which they were formed. “The computer was then tasked with identifying the combination of properties that would best explain the experimentally established tissue-specific selection of exons.”. In other words, the researchers reverse engineered the code. Like the codebreakers of World War II, once scientists know the algorithm, they can make predictions: “It correctly and accurately identified alternative exons and predicted their differential regulation between pairs of tissue types.” And just like any good scientific theory, the discovery provided new insight: “This allowed us to provide new insight into previously identified regulatory motifs and pointed to previously unknown properties of known regulators, as well as unexpected functional connections between them.”, the researchers noted. “For example, the code implies that the inclusion of exons leading to processed proteins is a general mechanism for controlling the process of gene expression during the transition from embryonic tissue to adult tissue.”.
Tejedor and Valcárcel consider the publication of their paper an important first step: “The work... is better viewed as the discovery of the first fragment of a much larger Rosetta Stone needed to decipher the alternative messages of our genome.” According to these scientists, future research will undoubtedly improve their knowledge of this new code. At the conclusion of their article, they briefly mention evolution, and they do so in a very unusual way. They say, “It doesn't mean that evolution created these codes. This means that progress will require understanding how the codes interact. Another surprise was that the degree of conservation observed to date raises the question of the possible existence of “species-specific codes.”.
The code probably operates in every single cell and therefore must be responsible for more than 200 types of mammalian cells. It must also cope with a huge variety of alternative splicing patterns, not to mention simple decisions to include or skip a single exon. The limited evolutionary conservation of alternative splicing regulation (estimated to be about 20% between humans and mice) raises the question of the existence of species-specific codes. Moreover, the link between DNA processing and gene transcription influences alternative splicing, and recent evidence points to DNA packaging by histone proteins and covalent modifications of histones (the so-called epigenetic code) in regulating splicing. Therefore, future methods will have to establish the precise interaction between the histone code and the splicing code. The same applies to the still little understood influence of complex RNA structures on alternative splicing.
Codes, codes and more codes. The fact that scientists say virtually nothing about Darwinism in these articles indicates that evolutionary theorists who adhere to old ideas and traditions have a lot to think about after they read these articles. But those who are enthusiastic about the biology of codes will find themselves at the forefront. They have a great opportunity to take advantage of the exciting web application that codebreakers have created to encourage further research. It can be found on the University of Toronto website called Alternative Splicing Prediction Website. Visitors will look in vain for any mention of evolution here, despite the old axiom that nothing in biology makes sense without it. The new 2010 version of this expression might sound like this: “Nothing in biology makes sense unless viewed in the light of computer science.” .
We're glad we were able to tell you about this story the day it was published. This may be one of the most significant scientific articles of the year. (Of course, every big discovery made by other groups of scientists, like Watson and Crick's, is significant.) The only thing we can say to this is: “Wow!” This discovery is a remarkable confirmation of Creation by design and a huge challenge to the Darwinian empire. I wonder how evolutionists will try to correct their simplistic story of random mutation and natural selection, which dates back to the 19th century, in light of these new data.
Do you understand what Tejedor and Valcárcel are talking about? Species can have their own code, unique to those species. “It will therefore be up to future methods to establish the precise interaction between the histone [epigenetic] code and the splicing code,” they note. Translated, this means: “Darwinists have nothing to do with this. They just can't handle it." If the simple Watson-Crick genetic code was a problem for Darwinians, what would they now say about a splicing code that creates thousands of transcripts from the same genes? How do they cope with the epigenetic code that controls gene expression? And who knows, maybe in this incredible “interaction”, which we are just beginning to learn about, other codes are involved, reminiscent of the Rosetta Stone, just beginning to emerge from the sand?
Now, when we think about codes and computer science, we begin to think about different paradigms for new research. What if the genome acts in part as a storage network? What if it involves cryptography or compression algorithms? We should remember about modern information systems and information storage technologies. We may even discover elements of steganography. There are undoubtedly additional mechanisms of resistance, such as duplications and corrections, that may help explain the existence of pseudogenes. Copies of the entire genome may be a response to stress. Some of these phenomena may be useful indicators of historical events that have nothing to do with a universal common ancestor, but help explore comparative genomics within the framework of computer science and resistance design, and help understand the cause of disease.
Evolutionists find themselves in a great difficulty. Researchers tried to modify the code, but all they got was cancer and mutations. How are they going to navigate the field of fitness if it is all mined with disasters waiting to happen as soon as someone starts interfering with these inextricably linked codes? We know that there is some built-in stability and portability, but the whole picture is an incredibly complex, designed, optimized information system, not a haphazard collection of parts that can be played with endlessly. The whole idea of code is the concept of intelligent design.
A. E. Wilder-Smith attached particular importance to this. The code assumes an agreement between the two parts. An agreement is an agreement in advance. It involves planning and purpose. We use the SOS symbol, as Wilder-Smith would say, by convention as a distress signal. SOS does not look like a disaster. It doesn't smell like a disaster. It doesn't feel like a disaster. People would not understand that these letters represent disaster if they did not understand the essence of the agreement itself. Likewise, the codon for alanine, HCC, does not look, smell, or feel like alanine. The codon would have nothing to do with alanine unless there was a pre-established agreement between the two coding systems (the protein code and the DNA code) that "GCC must mean alanine." To convey this agreement, a family of transducers, aminoacyl-tRNA synthetases, are used, which translate one code into another.
This was to strengthen design theory in the 1950s and many creationists preached it effectively. But evolutionists are like smooth-talking salesmen. They created their fairy tales about Tinkerbell, who breaks code and creates new species through mutation and selection, and convinced many people that miracles could still happen today. Well, well, today we are in the 21st century and we know the epigenetic code and the splicing code - two codes that are much more complex and dynamic than the simple DNA code. We know about codes within codes, about codes above codes and below codes - we know a whole hierarchy of codes. This time the evolutionists cannot simply stick their finger in the gun and bluff us with their beautiful speeches, when on both sides there are guns - an entire arsenal aimed at their main design elements. It's all a game. A whole era of computer science has grown up around them, they have long gone out of fashion and look like the Greeks who are trying to climb modern tanks and helicopters with spears.
It's sad to say, but evolutionists don't understand this, or even if they do, they're not going to give up. By the way, this week, just as the article on the Splicing Code was published, the most angry and hateful rhetoric against creationism and intelligent design in recent memory poured out from the pages of pro-Darwin magazines and newspapers. We are yet to hear of many more similar examples. And as long as they hold the microphones and control the institutions, many people will fall for their bait, thinking that science continues to give them good reason. We tell you all this so that you will read this material, study it, understand it, and equip yourself with the information you need to defeat this bigoted, misleading nonsense with the truth. Now, go ahead!
07.04.2015 13.10.2015
In the era of nanotechnology and innovation in all spheres of human life, you need to know a lot for self-confidence and communication with people. Technologies of the twenty-first century have come very far, for example, in the field of medicine and genetics. In this article we will try to describe in detail the most important step of humanity in DNA research.
What is this code? The code is degenerate by genetic properties and geneticists are studying it. All living beings on our planet are endowed with this code. Scientifically defined as a method of protein sequencing of amino acids using a chain of nucleotides.
Humanity has been studying proteins and acids for a long time, but the first hypotheses and the establishment of the theory of heredity arose only in the middle of the twentieth century. At this point, scientists have collected a sufficient amount of knowledge on this issue.
The records of various world scientists, which were different, were compared. Therefore, a certain concept was formed: each gene corresponds to a specific polypeptide. At the same time, the name DNA appeared, which was definitely proven not to be a protein.
Subsequently, it remained to understand only the issue of determining and forming protein amino acid chains, bases and properties.
 The first scientist to construct the genetic coding hypothesis was the physicist Gamow, who also proposed a certain way to test the matrix.
The first scientist to construct the genetic coding hypothesis was the physicist Gamow, who also proposed a certain way to test the matrix.One protein is made up of several strings of amino acids. The logic of connecting chains determines the structure and characteristics of the body’s protein, which accordingly helps to identify information about the biological parameters of a living being.
Information from living cells is obtained by two matrix processes:

Advances in molecular biology of the twentieth century allowed for great strides in the study of diseases and viruses with various causes. Information about the genetic code is widely used in medicine and genetics.
Since it has been scientifically proven that the genetic code contains information not only about heredity, but also about the life expectancy of the organism, the development of genetics asks the question of immortality and longevity. This prospect is supported by a number of hypotheses of terrestrial immortality, cancer cells, and human stem cells.
In 1985, a researcher at a technical institute, P. Garyaev, discovered, by accident of spectral analysis, an empty space, which was later called a phantom. Phantoms detect dead genetic molecules.
The genetic code is usually understood as a system of signs indicating the sequential arrangement of nucleotide compounds in DNA and RNA, which corresponds to another sign system displaying the sequence of amino acid compounds in a protein molecule.
It is important!
When scientists managed to study the properties of the genetic code, universality was recognized as one of the main ones. Yes, strange as it may sound, everything is united by one, universal, common genetic code. It was formed over a long period of time, and the process ended about 3.5 billion years ago. Consequently, traces of its evolution can be traced in the structure of the code, from its inception to the present day.
When we talk about the sequence of arrangement of elements in the genetic code, we mean that it is far from chaotic, but has a strictly defined order. And this also largely determines the properties of the genetic code. This is equivalent to the arrangement of letters and syllables in words. Once we break the usual order, most of what we read on the pages of books or newspapers will turn into ridiculous gobbledygook.
Basic properties of the genetic code
Usually the code contains some information encrypted in a special way. In order to decipher the code, you need to know the distinctive features.
So, the main properties of the genetic code are:
Let's take a closer look at each property.
1. Triplety
This is when three nucleotide compounds form a sequential chain within a molecule (i.e. DNA or RNA). As a result, a triplet compound is created or encodes one of the amino acids, its location in the peptide chain.
Codons (they are also code words!) are distinguished by their sequence of connections and by the type of those nitrogenous compounds (nucleotides) that are part of them.
In genetics, it is customary to distinguish 64 codon types. They can form combinations of four types of nucleotides, 3 in each. This is equivalent to raising the number 4 to the third power. Thus, the formation of 64 nucleotide combinations is possible.
2. Redundancy of the genetic code
This property is observed when several codons are required to encrypt one amino acid, usually in the range of 2-6. And only tryptophan can be encoded using one triplet.
3. Unambiguity
It is included in the properties of the genetic code as an indicator of healthy genetic inheritance. For example, the GAA triplet, which is in sixth place in the chain, can tell doctors about the good state of the blood, about normal hemoglobin. It is he who carries information about hemoglobin, and it is also encoded by it. And if a person has anemia, one of the nucleotides is replaced by another letter of the code - U, which is a signal of the disease.
4. Continuity
When recording this property of the genetic code, it should be remembered that codons, like links in a chain, are located not at a distance, but in direct proximity, one after another in the nucleic acid chain, and this chain is not interrupted - it has no beginning or end.
5. Versatility
We should never forget that everything on Earth is united by a common genetic code. And therefore, in primates and humans, in insects and birds, in a hundred-year-old baobab tree and a blade of grass that has barely emerged from the ground, similar triplets are encoded by similar amino acids.
It is in genes that the basic information about the properties of a particular organism is contained, a kind of program that the organism inherits from those who lived earlier and which exists as a genetic code.
- a unified system for recording hereditary information in nucleic acid molecules in the form of a nucleotide sequence. The genetic code is based on the use of an alphabet consisting of only four letters-nucleotides, distinguished by nitrogenous bases: A, T, G, C.
The main properties of the genetic code are as follows:
1. The genetic code is triplet. A triplet (codon) is a sequence of three nucleotides encoding one amino acid. Since proteins contain 20 amino acids, it is obvious that each of them cannot be encoded by one nucleotide (since there are only four types of nucleotides in DNA, in this case 16 amino acids remain unencoded). Two nucleotides are also not enough to encode amino acids, since in this case only 16 amino acids can be encoded. This means that the smallest number of nucleotides encoding one amino acid is three. (In this case, the number of possible nucleotide triplets is 4 3 = 64).
2. Redundancy (degeneracy) of the code is a consequence of its triplet nature and means that one amino acid can be encoded by several triplets (since there are 20 amino acids and 64 triplets). The exceptions are methionine and tryptophan, which are encoded by only one triplet. In addition, some triplets perform specific functions. So, in the mRNA molecule, three of them UAA, UAG, UGA are stop codons, i.e. stop signals that stop the synthesis of the polypeptide chain. The triplet corresponding to methionine (AUG), located at the beginning of the DNA chain, does not code for an amino acid, but performs the function of initiating (exciting) reading.
3. Along with redundancy, the code is characterized by the property of unambiguity, which means that each codon corresponds to only one specific amino acid.
4. The code is collinear, i.e. the sequence of nucleotides in a gene exactly matches the sequence of amino acids in a protein.
5. The genetic code is non-overlapping and compact, that is, it does not contain “punctuation marks.” This means that the reading process does not allow for the possibility of overlapping columns (triplets), and, starting at a certain codon, reading proceeds continuously, triplet after triplet, until the stop signals (termination codons). For example, in mRNA the following sequence of nitrogenous bases AUGGGUGTSUAUAUGUG will be read only by such triplets: AUG, GUG, TSUU, AAU, GUG, and not AUG, UGG, GGU, GUG, etc. or AUG, GGU, UGC, CUU, etc. etc. or in some other way (for example, codon AUG, punctuation mark G, codon UGC, punctuation mark U, etc.).
6. The genetic code is universal, that is, the nuclear genes of all organisms encode information about proteins in the same way, regardless of the level of organization and systematic position of these organisms.
They line up in chains and thus produce sequences of genetic letters.
Genetic code
The proteins of almost all living organisms are built from only 20 types of amino acids. These amino acids are called canonical. Each protein is a chain or several chains of amino acids connected in a strictly defined sequence. This sequence determines the structure of the protein, and therefore all its biological properties.
CUU (Leu/L)Leucine
CUC (Leu/L)Leucine
CUA (Leu/L)Leucine
CUG (Leu/L)Leucine
In some proteins, nonstandard amino acids, such as selenocysteine and pyrrolysine, are inserted by a ribosome reading the stop codon, depending on the sequences in the mRNA. Selenocysteine is now considered to be the 21st, and pyrrolysine the 22nd, amino acids that make up proteins.
Despite these exceptions, all living organisms have common genetic codes: a codon consists of three nucleotides, where the first two are decisive; codons are translated by tRNA and ribosomes into an amino acid sequence.
| Example | Codon | Normal meaning | Reads like: |
|---|---|---|---|
| Some types of yeast Candida | C.U.G. | Leucine | Serin |
| Mitochondria, in particular in Saccharomyces cerevisiae | CU(U, C, A, G) | Leucine | Serin |
| Mitochondria of higher plants | CGG | Arginine | Tryptophan |
| Mitochondria (in all studied organisms without exception) | U.G.A. | Stop | Tryptophan |
| Mitochondria in mammals, Drosophila, S. cerevisiae and many protozoa | AUA | Isoleucine | Methionine = Start |
| Prokaryotes | G.U.G. | Valin | Start |
| Eukaryotes (rare) | C.U.G. | Leucine | Start |
| Eukaryotes (rare) | G.U.G. | Valin | Start |
| Prokaryotes (rare) | UUG | Leucine | Start |
| Eukaryotes (rare) | A.C.G. | Threonine | Start |
| Mammalian mitochondria | AGC, AGU | Serin | Stop |
| Drosophila mitochondria | A.G.A. | Arginine | Stop |
| Mammalian mitochondria | AG(A, G) | Arginine | Stop |
However, in the early 60s of the 20th century, new data revealed the inconsistency of the “code without commas” hypothesis. Then experiments showed that codons, considered meaningless by Crick, could provoke protein synthesis in vitro, and by 1965 the meaning of all 64 triplets was established. It turned out that some codons are simply redundant, that is, a whole series of amino acids are encoded by two, four or even six triplets.
Wikimedia Foundation. 2010.

In 2018, the Nativity Fast will begin on November 28. During this period, Orthodox believers prepare to celebrate Christmas...

Starting a family is the dream of most women. They want to have a loving husband and a bunch of kids. But it's not always a relationship...

This article contains: the most powerful prayer for divorce - information taken from all over the world, the electronic network and...

Information site about icons, prayers, Orthodox traditions. Prayer for scandals and quarrels in the family, with husband, with children...

What would New Year be without champagne, tangerines, Olivier, aspic and everyone’s favorite “Herring under a fur coat”. With the last one...

Let's prepare the necessary ingredients for the cookies. The first thing to do is put the water to boil. We need...

Is it possible to register an employee for the position of financial director - chief accountant? The chief accountant claims...

The head of a small business can easily manage the budget independently. CHECKED! If you manage...

The creation of new projects involves a preliminary economic justification for their feasibility, subsequent...
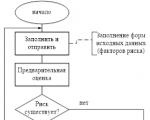
Reporting is generated by the RM, is agreed upon (approved) by the Risk Committee under the Management Board and transmitted to...

At the edge of a large, very large meadow, on a long emerald blade of grass lived a tiny Ladybug. God's little...

Nowadays, it is quite common for people to turn to the stars. With the help of a horoscope a person can find out...

Business or friendly. If you were pursuing a stranger, it means your level of trust in the female sex...

according to Freud's dream book If you dreamed about how you were fishing, it means that in real life you can hardly switch off...

Starting a family is the dream of most women. They want to have a loving husband and a bunch of kids. But it's not always...

This article contains: the most powerful prayer for divorce - information taken from all over the world, electronic...