What is possible and not possible during the Nativity Fast?
In 2018, the Nativity Fast will begin on November 28. During this period, Orthodox believers prepare to celebrate Christmas...
This page is a chapter from our teaching guide
"Introduction to Ontology Modeling"
(click to go to the full version of the manual in PDF format).
Science fiction writers of the 20th century thought that the development of computers would lead to the emergence of intelligent human assistants who would solve many mental problems for him. The capabilities of today's technology exceed the wildest predictions of many of these authors: a computer fits in the palm of your hand, the World Wide Web is accessible almost everywhere. At the same time, to solve analytical problems, in most cases we still use, at best, spreadsheets like Excel. This is especially noticeable in the business environment, where the cost of a (wrong) decision has a very tangible equivalent in the form of multi-billion dollar profits or losses. However, the development of business information infrastructure is stuck on the path of creating large “three-letter systems” (ERP, CRM, etc.), on which huge amounts of money are spent, but which are not able to give the owner organization anything particularly “intelligent”. Modern business intelligence (BI) systems are mainly concerned with calculating the values of quantitative indicators, which often have very little relation to the description of reality, and manipulating them.
An excellent example is the business favorite EBITDA indicator: it characterizes profit, and for this reason is often used, for example, as a basis for calculating bonuses to top managers. However, it does not characterize the manager’s performance in the sense in which the owner intuitively evaluates it: after all, by reducing expenses, EBITDA can be increased. This is always interesting to a manager, but is not always true from the point of view of the strategic development of the enterprise. And when calculating this indicator by company divisions, the possibilities for manipulation open up to the greatest extent. Several departments contribute to most items of income and expenses; by setting up the calculation algorithm, you can easily “reward” the favorites and “punish” the undesirables. Of course, such maneuvers have nothing to do with achieving real operational efficiency of the enterprise.
Methodological problems are even more clearly visible when trying to solve optimization problems using quantitative methods. A typical approach to this issue is to formulate an “objective function,” which is a description of some qualitative state of the system, presented as a number - for example, “the provision of the population with such and such services.” Further, also in quantitative form, restrictions and variable parameters are set, and after calculations a certain set of “optimal” solutions is obtained. However, their practical implementation often leads to results that are contrary to the goals set, or has serious side effects. For example, it may easily turn out that the “average temperature in the hospital”—the provision of services—has reached the required values, but for certain groups of the population they have become completely unavailable. Or the quality of these services has decreased so much that they have practically lost their meaning for consumers. It is easy to understand that the root of the problem lies in the too serious model assumptions that were made when formalizing the target parameter.
These methodological problems are directly related to computing capabilities - more precisely, to the limitations of that part of them that the business community has mastered. After all, if a more complex and reliable algorithm for calculating any indicator cannot, in the opinion of the business customer, be implemented in the information system, this justifies the use of an incorrect, crude, but technologically understandable method of calculation. Thus, in essence, in the field of business, a person has so far only truly entrusted the computer with one function - adding and subtracting numbers. He still does everything else himself, and does it, in most cases, not very well.
Of course, we are only talking about the general trend; There are many counterexamples of the implementation of truly effective systems that help optimize certain processes, but almost all such systems have a narrow industry focus and contain hard-coded algorithms for solving problems. Thus, they do not have a systemic influence on the state of affairs.
What needs to be done for the computer to truly help us in solving intellectual business problems and to be able to support decision-making in any area? It is necessary to breathe into him a “spark of reason,” that is, teach him to “think” like we do. In fact, for this we need to reproduce in digital representation those information structures and processes that we ourselves use in the process of thinking: the conceptual apparatus, logical reasoning. Then we will be able to implement the processes of processing these structures, that is, simulate individual fragments of our cognitive abilities on a computer. After this, having obtained certain results, we can critically look at the modeled structures and processes and improve them. Combined with the ability of computers, inaccessible to humans, to quickly process huge volumes of information, this approach promises to provide an unprecedentedly high level of quality decision support from information systems.
It is no coincidence that we cited logical thinking as an example of a cognitive process that can be reproduced in a computing environment. There are other approaches, the most popular of which is the use of neural networks - that is, imitation of the processes that occur during the interaction of neurons in the brain. Using this kind of tools, problems of image recognition, speech recognition, etc. are successfully solved. Neural networks can also be “trained” for use as a decision support tool. However, with an increase in the number of factors required to assess a situation, the complexity of their structure, ways of influencing the situation, the capabilities of neural networks become less and less convincing: training takes more time, the results obtained are probabilistic in nature and do not provide logical provability. Going beyond a pre-limited range of situations leads to the impossibility of obtaining a result suitable for practical use from the neural network. Imitating logical thinking is free from most of these shortcomings, and correcting a logical circuit when conditions change requires much less effort than retraining a neural network. But when drawing up logical models, their correctness, consistency, and relevance, which depends on the person – the author of the model, becomes fundamentally important.
One of the main characteristics of human consciousness is that it is lazy. Our brain cuts off everything “unnecessary”, reducing our understanding of events and phenomena to fairly simple definitions. We see only black and white and make decisions without considering the vast majority of objective information.
A person suffers from the same sin when analyzing business processes and environments. Instead of perceiving a business as a complex system that cannot be simplified beyond a certain limit without a critical loss of reliability of analytical results, a person tries to reduce all evaluation and management criteria to a few numerical indicators. In this way, it is possible to simplify the resulting model and reduce the costs of its creation. But those who do this should not be surprised when their forecasts do not come true, and decisions made based on modeling turn out to be incorrect.
The main principle of quality analytics and knowledge-based management sounds like this: DON'T SIMPLIFY model without need.
Unfortunately, the computer technologies common today are not conducive to the implementation of this principle. If only Excel or relational databases are available to us as an analysis tool, the description of the business will inevitably have to be reduced to a limited set of numerical indicators. Therefore, one of the most pressing problems of IT development at the moment is to bring to widespread industrial use such technologies that make it possible to build truly complex and integrated information models, and with their help to solve those optimization, analytical, and operational tasks that other technical means are powerless to overcome. .
A promising, but somewhat underestimated direction for solving this problem today is the use of so-called semantic technologies. The ideas of automated processing of conceptualized knowledge have been repeatedly put forward by thinkers since the Renaissance, were used to a limited extent in the best years of the Soviet planned economy, but have only now grown to truly functional implementation. To date, all the necessary components of the methodology and technologies necessary for working with ontological models, which are the subject of processing using semantic technologies, have been created. The word "ontology" means a body of knowledge; The term “semantic technologies” emphasizes the fact that they provide work with the meaning of information. Thus, the transition from traditional IT to semantic technologies is a transition from working with data to working with knowledge. The difference between these two terms, which we use here exclusively as applied to the content of information systems, emphasizes the difference in the way information is used: to perceive and use data, a person is needed, a subject who has to perform the operation of comprehension, identifying the meaning of the data, and transferring it to the part of reality that interests you. Knowledge can be perceived directly, since it is already represented using the conceptual apparatus that a person uses. In addition, fully automatic operations can be performed with electronically presented knowledge (ontologies) - obtaining logical conclusions. The result of this process is new knowledge.
Gartner analysts called semantic technologies one of the most promising IT trends of 2013, but their optimism turned out to be premature. Why? All for the same reason - people are lazy, and creating semantic models requires serious mental effort. The more benefits and advantages over competitors will be received by those who undertake these efforts and transform them into real business results.
BEGINNING — Ontologies in corporate systems. Part IOntological systems can be used to solve business problems, create intelligent systems, and present knowledge on the Internet. The range of technologies related to this issue is very wide and includes multi-agent systems, automatic knowledge extraction from natural language texts, information retrieval, intelligent annotation, automatic compilation of abstracts, etc.
The second part of the article briefly discusses theoretical concepts, tools, and practical examples of application.
An ontology consists of terms (concepts), their definitions and attributes, as well as associated axioms and rules of inference.
Formal ontology model O= is an ordered triple of finite sets, where:
Ontology models are classified as follows:
Relations represent the type of interaction between the concepts of an SbA. An example of a binary relation is “is a part.” It should be noted that the relations that are advisable to use when creating an ontology are much less diverse than terms, and, as a rule, are not specific to a particular SbA (“part-whole”, “is a subclass”, “has an impact”, “is similar to " and so on.).
Axioms are used to model statements that are always true.
Certain types of connections can be made between concepts. A dictionary of terms in a specific application area, a thesaurus with its own concepts (concepts) and connections that define natural language terms can be considered as ontologies. Information retrieval methods are used to establish a connection between verbally defined concepts and the search for concepts of relevant queries. Well-known examples of this type of ontology are indexes of Internet information search engines.
To describe more complex systems, concepts such as extensible ontology model.
In order to implement various ontologies, it is necessary to develop languages for their representation that have sufficient expressive power and allow the user to avoid “low-level” problems.
A key point in ontology design is the choice of an appropriate ontology specification language. The purpose of such languages is to make it possible to specify additional machine-interpretable semantics of resources, to make the machine representation of data more similar to the state of affairs in the real world, and to significantly increase the expressive capabilities of conceptual modeling of loosely structured Web data.
The spread of the ontological approach to knowledge representation has contributed to the creation of various ontology representation languages and tools designed for their editing and analysis.
There are traditional ontology specification languages: Ontolingua, CycL, languages based on descriptive logics (such as LOOM), languages based on frames (OKBC, OCML, Flogic).
More recent languages are based on Web standards (XOL, SHOE, UPML). RDF(S), DAML, OIL, OWL were created specifically for the exchange of ontologies via the Web, which will be discussed below.
In general, the difference between traditional and Web ontology specification languages lies in the expressive capabilities of the domain description and some of the inference engine capabilities of these languages. Typical language primitives additionally include:
RDF language. As part of the project for the semantic interpretation of Internet information resources (Semantic Web), a standard for describing metadata about a document, the Resource Description Framework, using XML syntax, was proposed.
RDF uses an underlying data model "object - attribute - value" and is capable of playing the role of a universal language for describing the semantics of resources and the relationships between them. Resources are described as a directed labeled graph - each resource can have properties, which in turn can also be resources or their collections. All RDF vocabularies use a basic structure that describes resource classes and the types of relationships between them. This allows the use of heterogeneous decentralized dictionaries created for machine processing using different principles and methods. An important feature of the standard is extensibility: you can specify the structure of the source description using and extending such built-in concepts of RDF schemas as classes, properties, types, collections. The RDF schema model includes inheritance of classes and properties.
RDF has already received support from many leading software vendors. A number of software products have been developed that allow you to create RDF descriptions for various types of systems. It is assumed that it is possible to integrate existing information repositories into a common semantic description base and to integrate the RDF database concept with the MPEG format. RDF Schema is a standard proposed by the W3C for representing ontological knowledge. It specifies a set of all possible valid data schemas. Domain models are described through resources, properties and their values. RDFS provides good basic capabilities for describing domain type vocabularies. One of the limitations is the impossibility of expressing axiomatic knowledge using RDFS, that is, defining axioms and inference rules based on them.
DAML+OIL is a semantic markup language for Web resources that extends the RDF and RDF Schema standards with more complete modeling primitives. The latest version of DAML+OIL provides a rich set of constructs for creating ontology and marking up information in a way that can be read and understood by a machine.
The first proposals to describe an ontology based on RDFS were DARPA DAML-ONT (DARPA Agent Markup Language) and European Commission OIL (Ontology Inference Layer). These ontology specification and exchange standards were developed to support the process of knowledge sharing and knowledge integration. Based on these proposals, the joint solution DAML+OIL arose. The DAML+OIL ontology consists of: headers; class elements; property elements; instances.
OWL(Web Ontology Language) is a language for representing ontologies that extends the capabilities of XML, RDF, RDF Schema and DAML+OIL. This project involves the creation of a powerful semantic analysis engine. It is planned to address the limitations of DAML+OIL designs.
OWL ontologies are sequences of axioms and facts, as well as links to other ontologies. They contain a component for recording authorship and other detailed information, are Web documents, and can be referenced via a URI.
In the already mentioned Semantic Web project, the “machine processing of meaning” of content will be made as clear as possible by marking documents with a “full meaning” index based on the use of ontological terms. Thus, ontologies are seen as a key technology for use in the Semantic Web (Figure 1).
Ontologies play an important role in organizing Web-based knowledge processing and knowledge sharing. Ontologies, defined as shared formal concepts of specific domains, provide a common understanding of topics about which both people and applications can exchange information. Ontologies differ from XML schemas in that they are knowledge representations rather than message formats (most Web standards consist of a combination of message formats and protocol specifications).
One of the advantages of ontology is the availability of tool software for them, providing general domain-independent support for ontological analysis. There are a number of tools for ontological analysis that support editing, visualization, documentation, import and export of ontologies of different formats, their presentation, combination, and comparison.
Ontolingua. In addition to the ontology editor itself, this system contains a Webster network component designed to define concepts, a server that provides access to Ontolingua ontologies via the OKBC (Open Knowledge Base Connectivity) protocol, and Chimaera, a toolkit for analyzing and combining ontologies.
Protege is a freely distributed Java program designed for building (creating, editing and viewing) ontologies of a particular application area. It includes an ontology editor that allows you to design ontologies by expanding the hierarchical structure of abstract and concrete classes and slots. Based on the generated ontology, Protégé allows you to generate forms of knowledge acquisition for introducing instances of classes and subclasses.
The tool supports the use of the OWL language and allows you to generate HTML documents that display the structure of ontologies. Since it uses the frame model of knowledge representation OKVS, this allows it to be adapted for editing SbA models presented not in OWL, but in other formats (UML, XML, SHOE, DAML+OIL, RDF and RDFS, etc.).
DOE is a simple editor that allows the user to create ontologies. The ontology specification process consists of three stages.
At the first stage, the user builds a taxonomy of concepts and relationships, explicitly outlining the position of each element (concept) in the hierarchy. The user then indicates how the concept is specific relative to its “parent” and how the concept is similar or different from its “siblings”. The user can also add synonyms and encyclopedic definitions in multiple languages for all concepts.
In the second step, the two taxonomies are examined from different perspectives. The user can expand them with new objects or add restrictions on the areas of relationships.
At the third stage, the ontology can be translated into a knowledge representation language.
OntoEdit— a tool that provides viewing, verification and modification of the ontology. It supports the OIL and RDFS ontology representation languages, as well as the internal XML-based knowledge representation language OXML. Like Protégé, it is a standalone Java application, but its code is closed. OntoEdit Free is limited to 50 concepts, 50 relationships, and 50 instances.
OilEd-an autonomous graphical ontology editor developed within the framework of the Op-To-Knowledge project. It is freely distributed under the GPL Public License. The tool uses the OIL language to represent ontologies. OilEd does not support class instances.
WebOnto designed for viewing, creating and editing ontologies. It uses OCML (Operational Conceptual Modeling Language) to model ontologies. The user can create various structures, including classes with multiple inheritance. The tool has a number of useful features: viewing relationships, classes and rules, and it is possible to collaborate on the ontology of several users.
O.D.E.(Ontological Design Environment) interacts with users at the conceptual level, provides them with a set of tables to fill in (concepts, attributes, relationships) and automatically generates code in the LOOM, Ontolingua and FLogic languages. The tool was developed in WebODE, which integrates all ODE services into a single architecture, storing its ontologies in a relational database.
These tools are needed in order not only to enter and edit ontological information, but also to analyze it, performing typical operations on ontologies, for example:
PROMPT serves to combine and group ontologies. This is an addition to the Protégé system, implemented as a plugin. Given two ontologies that need to be combined, PROMPT builds a list of operations (for example, combining terms or copying them into a new ontology) and passes it to the user, who can perform one of the proposed operations. The list of operations is then modified to create a list of conflicts and their possible solutions. This is repeated until the new ontology is ready.
Chimaera is an interactive tool for combining ontology, based on the Ontolingua ontology editor.
IN OntoMerge the original ontologies are translated into a general representation in a special language.
OntoMorph defines a set of transformation operators that can be applied to the ontology.
OBSERVER combines ontologies with mapping information between them and finds synonyms in the source ontologies.
ONION is based on ontology algebra and provides tools for defining rules of articulation (connection) between ontologies.
Practical ontology development includes:
You can then create a knowledge base by defining individual instances of these classes, entering a value into a specific slot, and providing additional constraints for the slot.
Let us highlight some fundamental rules for ontology development. They seem quite categorical, but in many cases they will help make the right design decisions.
Knowing what the ontology is intended to be used for and how detailed or general it will be can influence many modeling decisions.
It is necessary to determine which of the alternatives will help better solve the problem and will be more visual, more extensible and easier to maintain. It should be remembered that ontology is a model of the real world, and the concepts in the ontology should reflect this reality.
Once an initial version of the ontology is defined, we can evaluate and debug it by using it in some applications and/or discussing it with domain experts. As a result, the initial ontology will likely need to be revised. And this iterative design process will continue throughout the entire life cycle of the ontology.
Reusing existing ontologies may be necessary if the system needs to interact with other applications that are already included in separate ontologies or controlled vocabularies. Many useful ontologies are already available electronically and can be imported. There are libraries of reusable ontologies, such as Ontolingua or DAML. There are also a number of publicly available commercial ontologies, such as UNSPSC, RosettaNet, DMOZ.
Despite the fact that many ontologies have already been developed that reflect knowledge about a wide variety of objects, when describing specific subjects of economic activity, it is necessary to take into account their specificity and introduce it into the corresponding ontological models.
An ontological representation of knowledge about economic entities that are part of a system can be used to combine their information resources into a single information space (Fig. 2).

The enterprise ontology contains classes of concepts with semantic relationships assigned to them. It consists of a set technological ontologies and organizational ontology, reflecting the organizational and functional structure of the enterprise: staffing (employees, administration, service personnel), partners, resources, etc. and the relationships between them. Technology ontologies contain concepts that describe production processes. General knowledge of the domain to which economic entities belong reflects industry ontology.
The developed ontologies will allow employees of the same industry or corporation to use common terminology and avoid mutual misunderstandings that can complicate cooperation and lead to serious losses (for example, the organizational ontology clearly reflects the mutual hierarchy and connections between divisions of the enterprise, as well as their areas of competence, and links to certain regulatory documents provide the same basis for negotiations). They will provide work with structured data sources for which a data schema can be built, that is, data types and relationships between them are described, and there is a formal way to obtain individual data elements. Examples of structured data sources include various databases (for example, relational and object), as well as loosely structured resources described in XML, RDF, OWL, DAML+OIL formats.
As an example of the practical use of ontological technology models, we will give the ONTOLOGIC system, designed for creating and supporting distributed systems of normative and reference information (RNI), maintaining dictionaries, reference books and classifiers and supporting a system for coding accounting objects (see Fig. 3).

The basis of the system is a technological environment for constant, real-time interaction between users: information consumers (employees of services and functional departments) and experts responsible for maintaining regulatory and reference information.
To ensure unambiguous identification and classification of objects in reference data systems, a methodology has been developed that uses an ontological model for the formal description of classified data, which ensures the identification of key properties of classification objects and the construction of a classification code based on them. Classes (groups of homogeneous products) are identified according to the principle of homogeneity of the set of technical and consumer characteristics, and for each material a classification code is generated, including a class code and codes of all properties and their values for a given material.
The ontology provides a consistent accumulation of any amount of information in a standard classification structure. This approach guarantees unambiguous identification of resources, regardless of different interpretations of their names by different manufacturers.
This technology provides for the creation of a standard solution for managing master data and master data for industrial enterprises, holdings and government agencies. SAP MDM (Master Data Management) is used as a technology platform, designed for the integration of various (including multi-platform) applications at the scale of a company, holding, industry, government agency, etc., as well as for organizing and managing industry or corporate regulatory reference information (master data).
TOVE (Toronto Virtual Enterprise). The goal of the project is to create a data model that should:
TOVE should ensure the construction of an integrated model of a certain subject area, consisting of the following ontologies: operations, states and time, organization, resources, products, service, production, price, quantity.
Ontolingua is a system developed at Stanford University that provides a distributed, collaborative environment for viewing, creating, editing, modifying, and using ontologies. The system server supports up to 150 active users, some of whom supplement the system with descriptions of their projects.
Among many other projects, Ontolingua uses the Enterprise project.
Enterprise Project. The goal of the project is to improve (where necessary, replace) existing modeling methods using a set of tools that allow the integration of various enterprise modeling methods and tools. It is planned to create tools that will provide: recording and description of a specific subject area; defining objectives and requirements (consistent with the ontology); identification and evaluation of solution options and alternative projects, implementation of the chosen strategy.
When developing tools independently, it is possible to use different terminology, which can lead to conflicts and ambiguity when integrating them. To solve this problem, an ontology was built, which specifies a set of frequently used and generally accepted terms, such as activity, process, organization, strategy, marketing.
KACTUS. The goal of the project is to build a methodology for reusing knowledge about technical systems during their life cycle. This is necessary to use the same knowledge bases for design, evaluation, operation, maintenance, redesign and training.
KACTUS supports an integrated approach that includes manufacturing, engineering and knowledge engineering methods, based on the creation of an ontological and computational basis for the reuse of acquired knowledge in parallel with various applications of the technical field. This is achieved by building a domain ontology and reusing it in various application areas. In addition, an attempt is made to combine these ontologies with existing standards (for example STEP), using ontologies where it is possible to record data about a specific area.
The main formalism in KACTUS is CML (Conceptual Modeling Language).
The KACTUS toolkit is an interactive environment in which you can experiment with theoretical results (organize ontology libraries, transform data between ontologies, make transformations for different formalisms), as well as carry out practical actions (viewing, editing and refining the ontology in different formalisms).
OntoSeek is an information retrieval system that is designed for semantically oriented information retrieval, combining an ontology-driven meaning mapping engine and powerful modeling systems.
SHOE (Simple HTML Ontology Extensions) allows authors to annotate their Web pages with semantic content. The main component of SHOE is an ontology, which contains information about a certain domain. Using this information, search and query tools provide a more relevant response to a query than existing search engines by enabling knowledge to be included in Web pages that intelligent agents can actually read. To do this, SHOE supplements HTML with a set of special tags to represent knowledge. SHOE allows you to discover knowledge using the taxonomy and inference rules that exist in the ontology.
Plinus. The goal of the project is semi-automatic knowledge extraction from natural language texts, in particular, literature on the mechanical properties of ceramic materials. Since the texts cover a wide range of concepts, many integrated ontologies are required to cover concepts such as ceramic materials and their properties, their processing methods, and various material defects such as cracks and pores. Ontology defines the language with which the semantic part of the dictionary is expressed.
The activities of individuals and organizations now increasingly depend on the information they have and their ability to use it effectively (extract knowledge). At the same time, some groups of people involved in information processing use special terms that other organizations use in a different context. At the same time, different organizations often use different symbols for the same concepts.
All this greatly complicates mutual understanding. Therefore, it is necessary to develop formalized knowledge representation models that would ensure information processing at the semantic level in knowledge management systems (KMS).
Currently, there is significant interest in control systems on the part of industrial companies that are aware of the high applied potential of knowledge-based systems and used to solve a number of practical problems of an enterprise (organization). Issues of knowledge management are becoming crucial for a developing economy, where knowledge is capitalized and, therefore, acquires a completely different status.
Ontologies play a decisive role in the model for describing knowledge, without which, according to experts, entry into any subject area is prohibited. Ontology design is a creative process, and therefore the potential applications of the ontology, as well as the designer's understanding of and perspective on the domain, will undoubtedly influence decision making.
Rogushina Yulia Vitalievna- Ph.D. physics and mathematics Sciences, senior researcher Institute of Software Systems NASU.
Kursk 2007
BBK Printed by decision
editorial and publishing council
Kursk State University
Reviewer -
: Textbook. allowance for university students. – Kursk: Publishing house of Kursk State University, 200. – 84 s.
The educational and methodological manual is devoted to the most promising approach to modeling subject areas - ontological. The basic concepts, definitions, methodology for the development and construction of ontologies are considered using the example of the educational knowledge base “Animal World”. One of the tools for constructing ontologies, Protégé, is considered.
Intended for senior students studying in the specialty......mathematical support and administration of information systems.
Introduction........................................................ .................................. 4
1. Theoretical aspects of constructing ontologies.................................. 5
1. 1. Definition of ontology................................................... ..... 5
1. 2. Models of ontology and ontological system.................................. 14
1. 3. Application of ontologies................................................. .... 21
1. 4. Ontology engineering tools.................................... 25
2. Creating a domain ontology in Protégé.......... 30
2. 1. Preliminary remarks.................................................... 30
2. 2. Basic information about Protégé.................................................. 37
2. 3. Creating a domain ontology in Protégé.... 40
3. Semester assignment.................................................... .......... 77
Project execution order:................................................... 77
Literature................................................. ............................ 82
Introduction
An expert system is a combination of three interdependent “modules”: a knowledge base, an inference engine, and a user interface. The inference engine and interface are usually combined and called the expert system shell. In this case, we can talk about two components: the shell and the knowledge base. The most important component among them, of course, is the knowledge base. The problem of an adequate method, or method, for modeling a subject area and, as a consequence, the formalization of knowledge with its subsequent entry into a knowledge base is, if not central, then at least important in the theory of artificial intelligence.
There are many methods for representing knowledge. These are well-known logical and frame methods, as well as semantic networks and production rules. When creating knowledge-based systems (expert systems undoubtedly belong to them), various methods of representing knowledge are used.
Each of these methods has its own advantages and disadvantages. At the moment, there is significant interest in the use of ontology as a knowledge base for knowledge-based systems. Note that in some literature the knowledge base is identified with ontology. Generally speaking, there is no unambiguous definition of a domain ontology; often the ontology is defined in a way that is beneficial to the developer at the moment. This and some other interesting problems related to ontologies, as well as issues of their technical implementation, are discussed in this manual.
Theoretical aspects of ontology construction
Definition of ontology
As noted earlier, knowledge representation is an important issue in artificial intelligence. The term “knowledge representation” can mean either a way of encoding knowledge in a knowledge base, or a formal system that is used to formalize knowledge.
The practice of developing knowledge-based systems for complex subject areas and problems has shown that in each subject area there is a certain structure that occupies an intermediate position between the knowledge representation used in the domain model and the domain model (knowledge base).
This structure is called the “domain ontology”.
In philosophy, ontology is a term that defines the doctrine of being, of existence, in contrast to epistemology - the doctrine of knowledge. From another point of view, ontology is knowledge formally presented on the basis of conceptualization. Conceptualization involves describing a set of objects and concepts, knowledge about them and connections between them.
Ontology is called an explicit specification of conceptualization. Formally, an ontology consists of terms organized into a taxonomy, their definitions and attributes, and their associated axioms and rules of inference.
In the simplest case, ontology describes only a hierarchy of concepts connected by categorization relationships. In more complex cases, suitable axioms are added to express other relationships between concepts and to constrain their intended interpretation.
With this in mind, an ontology is a knowledge base that describes facts that are assumed to always be true within a particular community based on the generally accepted meaning of the vocabulary used.
Let us highlight the following interpretations of this term:
1. Ontology as a philosophical discipline.
2. Ontology as an informal conceptual system.
3. Ontology as a formal view of semantics.
4. Ontology as a specification of “conceptualization”.
5. Ontology as a representation of a conceptual system through a logical theory, characterized by:
o special formal properties or
o only by its purpose
6. Ontology as a dictionary used by logical theory.
7. Ontology as a (meta-level) specification of logical theory.
Speaking about ontology within the framework of the first interpretation, we mean the philosophical discipline that studies the nature and organization of existence.
According to the second interpretation, ontology is a conceptual system that can act as the basis of a certain knowledge base. According to interpretation 3, the ontology on which the knowledge base is built is expressed in terms of suitable formal structures at the semantic level. Thus, these two interpretations treat ontology as a conceptual "semantic" entity, whether formal or informal, while interpretations 5-7 treat ontology as a special "syntactic" object. The fourth interpretation is one of the most problematic, since its precise meaning depends on the understanding of the terms "specification" and "conceptualization".
The first approach to defining the concept of “domain ontology,” conventionally called humanitarian, involves definitions in intuitively understandable terms. The second approach to defining the concept of ontology is conventionally called computer. Within this approach, computer languages are developed to represent ontologies.
The main advantage of the computer approach is the formality of the proposed means for describing ontologies. The definition of the concept of domain ontology within the framework of this approach does not clarify the substantive essence of this concept, but, on the contrary, obscures this essence with numerous technical details associated with computer implementation, and does not distinguish it from other concepts, in particular from the concept of a domain model (knowledge base ).
Within the third, mathematical approach, attempts are made to define the concept of ontology in mathematical terms or using mathematical constructs.
Ontology is a logical theory that limits the admissible models of a logical language. The ontology in this case must provide axioms that constrain the meaning of non-logical symbols (predicates and functions) of a logical language, used as "primitives" for specific representation purposes. The purpose of an ontology is to characterize conceptualization by limiting possible interpretations of non-logical symbols of a logical language in order to establish a consensus on how to describe knowledge using that language. Conceptualization is seen as a set of informal rules that limit the structure of a part of reality.
So, by domain ontology we mean:
1. Domain ontology is that part of the knowledge of a subject area regarding which it is assumed to be unchanged. The rest of the domain knowledge is expected to change but must remain consistent with the domain ontology.
2. Domain ontology is that part of domain knowledge that limits the meaning of domain terms. The meanings of domain terms are independent of the rest of the (changeable) part of domain knowledge.
3. Domain ontology is the set of conventions about a domain, another part of domain knowledge is the set of empirical and other laws of that domain. The ontology determines the degree to which domain experts agree on the meanings of terms.
4. Domain ontology is an explicitly given external approximation of an implicitly given conceptualization. A conceptualization is a subset of the set of all situations that can be represented. The set of situations corresponding to the knowledge base is a subset of conceptualization. This subset is some approximation of the set of situations that are possible in reality.
In what follows, for definiteness, we will assume that ontology - a formal explicit description of the concepts in the subject area under consideration (classes (sometimes called concepts)), the properties of each concept that describe the various properties and attributes of the concept (slots (sometimes called roles or properties)), and the restrictions imposed on the slots (facets) (sometimes called role restrictions)) . The ontology, together with a set of individual class instances, forms a knowledge base.
Let us give some reasons for the need to develop ontologies. So, ontologies are needed for:
· sharing of a common understanding of the structure of information by people or software agents;
· the possibility of reusing knowledge in the subject area;
· to make assumptions in the subject area explicit;
· separating domain knowledge from operational knowledge;
· analysis of knowledge in the subject area.
Sharing a common understanding of the structure of information between people or software agents is one of the most common goals of ontology development. For example, suppose several different websites contain information on medicine or provide information about paid medical services paid over the Internet. If these websites share and publish the same basic ontology of terms that they all use, then computer agents can extract information from these different sites and accumulate it. Agents can use the accumulated information to respond to user requests or as input to other applications.
Enable the use of domain knowledge has become one of the driving forces behind the recent surge in the study of ontologies. For example, for models of many different subject areas it is necessary to formulate the concept of time. This representation includes the concept of time intervals, moments in time, relative measures of time, etc. If one group of scientists develops such an ontology in detail, others can simply reuse it in their subject areas. Additionally, if we need to create a large ontology, we can integrate several existing ontologies that describe parts of a large domain. It is possible to reuse a basic ontology such as UNSPSC and extend it to describe a domain of interest.
Making Explicit Domain Assumptions underlying the implementation makes it easy to change these assumptions as our domain knowledge changes. Hard-coding assumptions about the world into a programming language makes those assumptions not only difficult to find and understand, but also difficult to change without being a programmer. In addition, explicit specifications of domain knowledge are useful for new users who need to learn the meaning of domain terms.
Separating domain knowledge from operational knowledge– This is another option for the general use of ontologies. We can describe the task of configuring a product from its components according to the required specification and implement a program that makes this configuration independent of the product and the components themselves. After this, we can develop an ontology of computer components and characteristics and apply this algorithm to configure non-standard computers. We can also use the same algorithm to configure elevators if we provide it with an ontology of elevator components.
Analysis of domain knowledge possible when there is a declarative specification of terms. Formal term analysis is extremely valuable both when attempting to reuse existing ontologies and when extending them.
The question often arises about the difference between an ontology and a database. Let us indicate the main differences between them.
The result of a database query is typically a collection of instance data and links to text documents, while the result of an ontology query may include elements of the ontology itself (for example, all subclasses of a particular class).
Ontologies themselves include semantics
Database schemas and catalogs typically do not provide external semantics for their data. The semantics were never defined, or the semantics were defined externally during database development, but the specification did not become part of the database specification and is no longer available. Therefore, when using databases, we need certain protocols to deal with the problem of conflicting constraints when changing the database. However, ontologies are logical systems that themselves include semantics.
Ontologies are more often reused
A database schema defines the structure of a particular database and other databases, and schemas are not often directly reused or extended. The circuit is part of an integrated system and is rarely used separately from it. With ontologies, the situation is exactly the opposite: ontologies usually reuse and extend other ontologies and they are not tied to a specific system.
Ontologies are decentralized by nature
Traditionally, developing and updating a database schema is a centralized process: the original schema's developers (or employees in the same organization) typically make changes and maintain the schema. At the very end, database schema developers usually know which databases are using their schema. By nature, ontology development is a much more decentralized and collaborative process. As a result, there is no central control over who uses a particular ontology. It is much more difficult (and perhaps impossible) to distribute or synchronize updates: we do not know who is using the ontology, we cannot tell them about the updates, and we cannot assume that they will know about it themselves. The lack of centralized and synchronized control also makes it difficult (and often impossible) to trace the sequence of operations that transformed one version of the ontology into another.
Ontology information models are richer
Many ontologies have many more representation primitives than a typical database schema. For example, many ontological languages and systems allow the specification of cardinality constraints, inverse properties, transitive properties, inverse classes, etc. Some languages (eg DAML+OIL) add primitives to define new classes as unions or intersections of other classes, as an enumeration of their members, as a set of objects that satisfy a certain constraint.
Classes and instances can be the same
Databases clearly distinguish between schema information and instance information. In many powerful knowledge representation systems, it is difficult to determine where the ontology ends and the instances begin. The use of metaclasses (classes that use other classes as instances) in many systems (eg Protégé, Ontolingua, RDFS) blurs or erases the boundary between classes and instances. Metaclasses are sets whose elements are also sets. This means that "instance" and "class" are really just roles of the concept.
Models of ontology and ontological system
The concept of ontology involves the definition and use of an interrelated and mutually agreed upon set of three components: a taxonomy of terms, definitions of terms and rules for their processing. Let us introduce the following definition of the concept of an ontology model:
By formal model of ontology O we mean
X is a finite set of concepts (concepts, terms) of the subject area, which is represented by ontology O;
R – a finite set of relations between concepts (concepts, terms) of a given subject area;
F is a finite set of interpretation (axiomatization) functions defined on the concepts and/or relations of the ontology O.
A natural limitation imposed on the set X is its finiteness and non-emptiness. The situation is different with the components F and R in the definition of ontology O. It is clear that in this case, F and R must be finite sets. Let us indicate the boundary cases associated with their emptiness.
1. Let and . Then the ontology O is transformed into a simple dictionary:
![]() .
.
Such a degenerate ontology can be useful for specifying, enriching, and maintaining software vocabularies, but dictionary ontologies have limited use because they do not explicitly introduce the meaning of terms. Although in some cases, when the terms used belong to a very narrow (for example, technical) vocabulary and their meanings are already well agreed upon within a certain (for example, scientific) community, such ontologies are used in practice. Well-known examples of this type of ontology are indexes of information retrieval machines on the Internet.
2. . . Then each element of the set of terms from X can be associated with an interpretation function f from F. Formally, this statement can be written as follows.
where is the set of interpreted terms;
Lots of interpretive terms.
such that
![]()
The emptiness of the intersection of sets excludes cyclic interpretations, and the introduction of k arguments into the consideration of the function is intended to provide a more complete interpretation. The type of mapping f from F determines the expressive power and practical usefulness of this type of ontology. If the interpretation function is specified by the value assignment operator (), where is the name of the interpretation), then the ontology is transformed into a passive dictionary:
Such a dictionary is passive, since all definitions of terms are taken from an already existing and fixed set. Its practical value is higher than that of a simple dictionary, but it is clearly insufficient, for example, for representing knowledge in information processing tasks on the Internet due to the dynamic nature of this environment.
In order to take into account the last circumstance, let us assume that some of the interpreting terms from the set are specified procedurally, rather than declaratively, and are calculated each time a term from the set is interpreted. In this case, the ontology is transformed into an active dictionary of definitions
Moreover ![]()
The value of such a dictionary for information processing tasks in the Internet environment is higher than that of the previous model, but is still insufficient, since the interpreted elements are not interconnected in any way and, therefore, play only the role of entry keys into the ontology.
To present an ontology model that is needed to solve problems of information processing on the Internet.
Let's consider possible options for forming a set of relationships based on ontology concepts.
Let us introduce into consideration a special subclass of ontology - a simple taxonomy as follows:
Taxonomic structure - a hierarchical system of concepts interconnected by the relation is_a (“to be an element of a class”).
The is_a relation has pre-fixed semantics and allows you to organize the structure of ontology concepts in the form of a tree.
Classification of ontology models
| Model components | . | |||
| Formal definition | | | |
|
| Explanation | Software Dictionary | Passive software dictionary | Active software dictionary | Taxonomy of software concepts |
Representations of a set of concepts X in the form of a network structure;
Using a fairly rich set of relations R, including not only taxonomic relations, but also relations reflecting the specifics of a particular subject area, as well as means of expanding the set R;
Use of declarative and procedural interpretations and relationships, including the ability to define new interpretations.
Let us introduce the concept of an ontological system. A formal model of an ontological system is understood as a triplet of the form:
![]()
where is the top-level ontology (metaontology)
Many subject ontologies and ontologies of domain problems
Model of an inference engine associated with an ontological system.
The use of an ontology system and a special inference engine makes it possible to solve various problems in such a model. By expanding the system of models, you can take into account user preferences, and by changing the model of the inference engine, you can introduce specialized criteria for the relevance of the information obtained during the search process and create special repositories of accumulated data, as well as replenish the ontologies used if necessary.
The model has three ontological components:
Metaontology;
Subject ontology;
Ontology of tasks.
Metaontology operates with general concepts and relationships that do not depend on a specific subject area. Meta-level concepts are general concepts such as “object”, “property”, “meaning”, etc. Metaontology levels receive an intensional description of the properties of the subject ontology and task ontology. The meta-level ontology is static, which makes it possible to provide efficient inference here.
A subject ontology contains concepts that describe a specific subject area, relations that are semantically significant for a given subject area, and many interpretations of these concepts and relations (declarative and procedural). Domain concepts are specific in each applied ontology, but relationships are more universal. Therefore, as a basis, such relations of the subject ontology model are usually distinguished as part_of, kind_of, contained_in, member_of, see also and some others.
Attitude part_of defined on a set of concepts, is a relation of membership and shows that a concept can be part of other concepts. It is a “part-whole” type relation and its properties are close to the relation is_a and can be specified by the corresponding axioms. In a similar way, other “part-whole” relationships can be introduced.
The situation is different with attitude see_also. It has different semantics and other properties. Therefore, it is advisable to introduce it not declaratively, but procedurally, just as is done when defining new types in programming languages that support abstract data types.
 The ontology of tasks as concepts contains the types of tasks to be solved, and the relations of this ontology, as a rule, specify the decomposition of tasks into subtasks. At the same time, if the application system solves a single type of task (for example, the task of searching for information relevant to a request), then the ontology of tasks can in this case be described by a dictionary. Thus, the ontological system model allows us to describe the ontologies of different levels necessary for its functioning. The relationship between ontologies is shown in the figure:
The ontology of tasks as concepts contains the types of tasks to be solved, and the relations of this ontology, as a rule, specify the decomposition of tasks into subtasks. At the same time, if the application system solves a single type of task (for example, the task of searching for information relevant to a request), then the ontology of tasks can in this case be described by a dictionary. Thus, the ontological system model allows us to describe the ontologies of different levels necessary for its functioning. The relationship between ontologies is shown in the figure:
In the general case, the inference engine of an ontological system can rely on a network representation of the ontology at all levels. In this case, its functioning will be related to:
With the activation of concepts and/or relations that fix the problem being solved (description of the initial situation);
Determining the target state (situation);
The conclusion on the network is that activation waves propagate from the nodes of the initial situation, using the properties of the relations associated with them. The criterion for stopping the process is the achievement of the target situation or exceeding the execution duration (time-out).
Application of ontologies
Summarizing the various ontology typifications, we can distinguish classifications according to:
Degree of dependence on a specific task or subject area;
Level of detail of axiomatization;
the “nature” of the subject area, etc.
In addition to these dimensions, classifications related to the development, implementation and maintenance of the ontology can be introduced.
Based on the degree of dependence on a specific task or subject area, they are usually distinguished:
Top level ontologies;
Domain-oriented ontologies;
Ontologies focused on a specific task;
Applied ontologies.
Top-level ontologies describe very general concepts such as space, time, matter, object, event, action, etc., which are independent of a specific problem or domain. It therefore seems reasonable, at least in theory, to unify them across large communities of users.
An example of such a general ontology is CYC®. The project of the same name - CYC® - is focused on creating a multi-context knowledge base and a special inference engine developed by Susogr. The main goal of this gigantic project is to build a knowledge base of all general concepts (starting with such as time, essence, etc.), including the semantic structure of terms, connections between them and axioms. It is assumed that such a knowledge base can be accessible to a variety of software tools that work with knowledge, and will play the role of an “initial knowledge” base. According to some data, the ontology already contains 10 6 concepts and 10 5 axioms. A special language, CYCL, has been developed to represent knowledge within the framework of this project.
Another example of a top-level ontology is the ontology of the Gene-railized Upper Model system, focused on supporting natural language processing processes: English, German and Italian. The level of abstraction of this ontology is between lexical and conceptual knowledge, which is determined by the requirements to simplify interfaces with linguistic resources. The Generalized Upper Model includes a taxonomy organized into a hierarchy of concepts (about 250 concepts) and a separate hierarchy of relationships.
Creating sufficiently general top-level ontologies is a very serious task that does not yet have a satisfactory solution.
Subject ontologies and task ontologies describe, respectively, a vocabulary associated with a subject area (medicine, commerce, etc.) or with a specific task or activity (diagnosis, sales, etc.) due to the specialization of terms introduced in the ontology of the upper level. Examples of domain-specific and task-specific ontologies are TOVE and Plinius, respectively.
The ontology in the TOVE (Toronto Virtual Enterprise Project) system is subject-oriented to represent the corporation model. The main goal of its development is to answer user questions on business process reengineering by extracting knowledge explicitly presented in the ontology. In this case, the system can conduct deductive inference of answers. The ontology does not have tools for integration with other ontologies. Formally, the ontology is described using frames.
Currently, ontologies have been built for some sections of molecular biology, which offer terminology for defining many chemical elements and describing processes inside the cell. The TAMBIS Ontology (TaO) describes bioinformatics, covers the basic concepts of molecular biology and bioinformatics: macromolecules, their purpose, structure, functions, cellular location and processes in which they interact. The Tao ontology is built using the OIL language.
There is also an experimental ontology for bioinorganic centers known as COME. COME consists of three types of entities: Molecule (MOL), Bioinorganic Motif (BIM) and Bioinorganic Proteins (PRX).
Ontologies have also been built that represent concepts and relationships in more narrowly focused areas - such as chemical crystals, ceramic materials, bioenergy centers. An example of such ontologies is the Chemical-Crystals ontology. The Chemical-Crystals ontology describes the different types of crystal structure of substances. This ontology is built using a methodology known as METHONTOLOG.
Another example of ontology is the ontology of pure substances. The definition of pure substances is given through chemical composition, i.e. through structural rules that define pure substances in terms of chemicals and natural numbers. A hierarchical ontology model of physical chemistry has been developed. The modular ontology of physical chemistry defines many sections of the subject area and the connections between them, describes the system of concepts of each section and defines the connections between the concepts of the sections. The ontology of physical chemistry consists of eight interconnected sections: “Elements”, “Substances”, “Reactions”, “Fundamentals of Thermodynamics”, “Thermodynamics. Chemical properties", "Thermodynamics. Physical properties", "Thermodynamics. Relationship between physical and chemical properties", "Chemical kinetics". The ontology of this subject area is based on a metaontology, which defines the metaconcepts used in defining the concept systems of each section.
Applied ontologies describe concepts that depend both on a specific subject area and on the tasks that are solved in them. Concepts in such ontologies often correspond to the roles that objects in a domain play in the process of performing a certain activity. An example of such an ontology is the ontology of the Plinius system, designed for semi-automatic knowledge extraction from texts in the field of chemistry. Unlike the other ontologies mentioned above, there is no explicit taxonomy of concepts.
Instead, several sets of atomic concepts are defined, such as, for example, a chemical element, an integer, etc., and rules for constructing the remaining concepts. The ontology describes about 150 concepts and 6 rules. Formally, the Plinius ontology is also described using frames.
The concept of substance in ontological systems. The concept of substance and being. Searches for the substantial basis of being in the history of philosophy. Substance as a self-determining basis of existential processes. A general idea of the relationship between spirit and matter, soul and body. Substance, spirit and mind. Categories “absolute”, “relative”, “universal”, “individual”, “essence” and “phenomenon” to resolve the issue of the relationship between substance and the forms of its manifestation. Materialism and idealism are about the nature of consciousness and thinking and their relationship with matter.
Materialistic substantialism. Varieties of constructing a materialist ontology. Sensual-material Cosmos as the main feature of ancient natural philosophy. Dialectical materialism as one of the variants of materialistic substantialism and its place in modern philosophy. Understanding of matter as an objective reality and as the substance of all processes in the world. The principle of materialistic unity of the world. Science and materialist philosophy. Modern ideas about the structure of matter, substance and fields. Hierarchy of material systems in the world. Structural infinity and eternity of matter as a substance. Universal attributes of matter. The relationship between the general and specific properties of matter. Structural levels of matter and forms of its systemic organization. Methods for identifying the universal properties of matter and proving their universality. Interaction and movement as attributes of matter. The relationship between interaction and communication. Types of relationships in the world. Asymmetry of causal relationships in irreversible changes. The problem of spreading connections and interactions in space and time. Is the world infinite or is it a connected integral formation, an integral system? Interaction and autonomy of material systems. Basic forms of motion of matter and criteria for their classification. The relationship between living and inanimate nature.
Idealistic substantialism. Varieties of idealistic substantialism in the history of philosophy. The idea of universalism of the world and the sensory-perceiving Cosmos in ancient philosophy. Ancient idealism. Religious and philosophical models of idealistic substantialism. Features of constructing an ontological system in logical idealism. Spiritually ideal principles of existence. The relationship between the ideal and the material in the idealistic interpretation. Attributes of an ideal substance: consciousness, goal setting, freedom, creativity. Consciousness as the ideal substantial basis of the world. The concept of eidos as a cause-and-goal structure of the world, as a self-thinking being in ancient philosophy. The ancient concept of the Cosmos as a “world subject”. Absolute spirit in Hegel's philosophy. The concept of the world cosmic mind. The concept of God in the history of religion and philosophy as the ideal substantial basis of the world. Logos and God.
Creationist variants of ontology. The relationship between God and the World in ontological systems of the Middle Ages. Reason and will. Divine spirit and human soul. Development of ideas about the soul. The soul as the bearer of consciousness and the entire spiritual world of man. The concept of spirituality. Spirituality and religiosity. The ideal-semantic content of consciousness and its ontological status. Achievements and limitations of idealistic ontology.
Personalistic substantialism. Man as a microcosm in Renaissance philosophy. The values of human existence and the place of Man in Space. Creativity as the main sign of a person’s special place in the world. Leibniz's monadology and ideal-realism N.O. Lossky. Dynamic understanding of matter. Anthropic principle in cosmology. Cosmic approach to man and consciousness. Features of ontological quests in Russian philosophy.
The crisis of ontology and antisubstantialist models of philosophy. The crisis of ontologism in the history of philosophy, the thesis about the “death of metaphysics” (prerequisites, motives, declarations and arguments). Being and consciousness: the problem of correspondence of philosophical ontological constructions to objective reality. Ontological picture of the world, the real world and the individual. Constructive and creative activity of the human “I” and criticism of ontology.
Ontological models in modern philosophy. Metaphysics rehabilitation programs and “new ontology” projects. Hierarchical models of ontology: Being as a set of forms of movement of matter by F. Engels. Layers of existence N. Hartmann. Regional ontologies of E. Husserl. The problem of identifying regional ontologies: ontology of society. Ontology of consciousness and self-awareness. Language ontology. Ontology of personal existence (existence). Ontology of corporeality. Ontology of culture. Variants of existential metaphysics: fundamental ontology of M. Heidegger. The world of transcendental existence by K. Jaspers.
Dialectical-materialist model of ontology. A materialistic solution to the fundamental question of philosophy. The concept of matter as objective reality. Structural levels of being.
The problem of typologizing ontological models. Monistic, pluralistic and dualistic ontologies. Essentialist and anti-essentialist ontologies. Hierarchical and non-hierarchical ontological constructions. Natural philosophical models. Theistic models. Existential-anthropological models. Phenomenological-hermeneutical models.
Genesis and development
The problem of movement in the history of philosophy. The relationship between movement, change and development. Basic properties of movement. Philosophical models of development: creationism, emanation theory, preformationism, emergentism, evolutionism. The variety of forms of movement and structural levels of existence. Changing and unchanging existence. The problem of movement in the history of philosophy. The problem of the universality of movement. Paradoxes of movement.
Development and emergence of new forms of being. Development and dialectics. Dialectical concepts of development. Their structure, laws, principles, basic concepts. The paradox of the emergence of something new. The problem of the relationship between the actual and the potential in development. Nonlinearity of development. Laws and categories of development.
Types of dialectics. Source, mechanism and direction of development. Philosophical laws describing the development of the world (G.W.F. Hegel, K. Marx, dialectical materialism). The law of unity, interaction and struggle of opposites. The law of mutual transition of quantitative and qualitative changes. The law of dialectical negation.
Modern views on the evolution of man, society and the Universe. Man, nature, space. The phenomenon of life and its place in the Universe. The problem of other forms of life in the Universe and the hypothesis about the uniqueness of the human mind (V. Shklovsky). The global crisis of technogenic-consumer civilization and the concept of the noosphere. Features of the anthropocosmic turn in modern science and culture.
Man as a “bio-logos” being.
"Logos" component of a person. Man as presence. The concept of "cultural machines". Basic phenomena of human existence. Man as a "symbolic" being. The structure of "symbolic space". Historical types of mentality. Transcendental conditions for the generation of symbols: declarativeness and human ability for synthetic acts. The human right to make mistakes. Progress and aggravation of global problems of humanity. Synergetics and self-organization processes in open nonlinear systems. Global evolutionism in the structure of modern consciousness. Self-organization processes in open nonlinear systems. Synergetics and its basic concepts (attractors, bifurcation points, fluctuations, fractals). Global evolutionism.
The role of information in development processes. Changing the system of communication means in the modern world as the most important condition for accelerating the pace of development.
The concept of ontology involves the definition and use of an interconnected and interdependent set of three components: O=<Х, К, Ф>, where X is a finite and non-empty set of concepts (concepts, terms) of the subject area, which is represented by ontology O; K is a finite set of relations between the concepts of a given subject area; Ф is a finite set of interpretation functions (axiomatization) defined on the concepts and/or relations of the ontology O. Let us consider the cases associated with the emptiness of K and F. Let K= and Ф=. Then the ontology is transformed into a simple dictionary:
O=< X 1 X 2 , {}, {:=}>. Dictionary ontologies have limited use because they do not explicitly introduce the meaning of terms. Although in some cases, when the terms used belong to a very narrow vocabulary and their meanings are already well agreed upon within a certain community, such ontologies are used in practice. It is these ontologies that are now widely used - these are indexes of information search engines on the Internet. The situation is different when using ordinary natural language terms or when software agents communicate. In this case, it is necessary to characterize the intended meaning of the dictionary elements using suitable axiomatization, the purpose of which is to exclude undesirable models and to ensure that the interpretation is the same for all participants in communication. Another option corresponds to the case K= , but Ф. Then each element of the set of terms X can be assigned a corresponding interpretation function f from F. Formally, this statement can be written as follows: Let X = X 1 X 2, Moreover, X 1 X 2 =, Where X 1 is the set of interpreted terms; X 2 – set of interpretive terms. Then (хХ 1, у 1, у 2, … у k Х 2), Such that Х=f(у 1, у 2, … у k), Where fФ. The emptiness of the intersection of the sets X 1 and X 2 excludes cyclic interpretations, and the introduction of k arguments into consideration of the function is intended to provide a more complete interpretation. The type of mapping f from Ф determines the expressive power and practical usefulness of this type of ontology. Thus, if we assume that the interpretation function is specified by the value assignment operator (X 1:=X 2), then the ontology is transformed into a passive dictionary: O=< X 1 X 2 , {}, {:=}>. Such a dictionary is passive, since all definitions of terms from X 1 are taken from the already existing fixed set X 2 . Its practical value is higher than that of a simple dictionary, but it is clearly insufficient, for example, for representing knowledge in information processing tasks on the Internet due to the dynamic nature of this environment. In order to take into account the last circumstance, we assume that some of the interpretive terms from the set X 2 are specified procedurally and not declaratively. The meaning of such terms is “calculated” each time they are interpreted. The value of such a dictionary for information processing tasks in the Internet environment is higher than that of the previous model, but is still insufficient, since the interpreted elements X 1 are not interconnected in any way and, therefore, play the role of entry keys into the ontology. To present the model that is needed to solve problems of information processing on the Internet, it is obviously necessary to abandon the assumption K=. Further, we can generalize special cases of the ontology model in such a way as to provide the ability to:
representation of multiple concepts in the form of a network structure;
using a fairly rich set K, including not only taxonomic relations, but also relationships reflecting the specifics of a particular subject area, as well as means of expanding the set K;
the use of declarative and procedural interpretations and relationships, including the ability to define new interpretations.
Then we can introduce an extensible ontology model into consideration. The extensible ontology model is powerful enough to specify the processes of forming knowledge spaces on the Internet. At the same time, this model is incomplete due to its passivity, even where the corresponding procedural interpretations are defined and special functions for replenishing the ontology are introduced. Let us introduce the concept of an ontological system. By the formal model of the ontological system о we mean a triplet of the form: о=
metaontology;
subject ontology;
task ontology.
As mentioned above, metaontology operates with general concepts and relationships that do not depend on a specific subject area. Meta-level concepts are general concepts. Then, at the level of metaontology, we obtain an intensional description of the properties of the subject ontology and the ontology of tasks. The meta-level ontology is static, which makes it possible to provide efficient inference here. A subject ontology contains concepts that describe a specific subject area, relations that are semantically significant for a given subject area, and many interpretations of these concepts and relations (declarative and procedural). Domain concepts are specific in each applied ontology, but relationships are more universal. Therefore, as a basis, such relations of the subject ontology model are usually distinguished as part_of, kind_of, contained_in, member_of, see_also and some others. The ontology of tasks as concepts contains the types of tasks to be solved, and the relations of this ontology, as a rule, specify the decomposition of tasks into subtasks. In the general case, the inference engine of an ontological system can rely on a network representation of ontologies at all levels. At the same time, its functioning will be associated with: the activation of concepts and/or relations that fix the problem being solved (description of the initial situation); determining the target state (situation); conclusion on the network, which consists in the fact that activation waves propagate from the nodes of the initial situation, using the properties of the relations associated with them. The criterion for stopping the process is the achievement of the target situation or exceeding the duration of execution.

In 2018, the Nativity Fast will begin on November 28. During this period, Orthodox believers prepare to celebrate Christmas...

Starting a family is the dream of most women. They want to have a loving husband and a bunch of kids. But it's not always a relationship...

This article contains: the most powerful prayer for divorce - information taken from all over the world, the electronic network and...

Information site about icons, prayers, Orthodox traditions. Prayer for scandals and quarrels in the family, with husband, with children...

What would New Year be without champagne, tangerines, Olivier, aspic and everyone’s favorite “Herring under a fur coat”. With the last one...

Let's prepare the necessary ingredients for the cookies. The first thing to do is put the water to boil. We need...

Is it possible to register an employee for the position of financial director - chief accountant? The chief accountant claims...

The head of a small business can easily manage the budget independently. CHECKED! If you manage...

The creation of new projects involves a preliminary economic justification for their feasibility, subsequent...
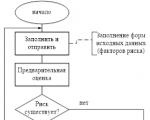
Reporting is generated by the RM, is agreed upon (approved) by the Risk Committee under the Management Board and transmitted to...

At the edge of a large, very large meadow, on a long emerald blade of grass lived a tiny Ladybug. God's little...

Nowadays, it is quite common for people to turn to the stars. With the help of a horoscope a person can find out...

Business or friendly. If you were pursuing a stranger, it means your level of trust in the female sex...

according to Freud's dream book If you dreamed about how you were fishing, it means that in real life you can hardly switch off...

Starting a family is the dream of most women. They want to have a loving husband and a bunch of kids. But it's not always...

This article contains: the most powerful prayer for divorce - information taken from all over the world, electronic...