Що можна і не можна на Різдвяний піст?
У 2018 році Різдвяний пост розпочнеться 28 листопада. У цей період православні віруючі готуються до зустрічі Різдва.
Наступна революція розумних роботів передбачалася кожні десять років, починаючи з 1950-х років. Проте вона так і не сталася. Прогрес в області штучного інтелектувідбувався невпевнено, часом нудно, несучи багатьом ентузіастам розчарування. Видимі успіхи - комп'ютер Deep Blue, створений у середині 1990-х IBM і обігравши в 1997 році Гаррі Каспарова в шахи, або поява наприкінці 1990-х електронного перекладача - були скоріше результатом «грубих» розрахунків, ніж перенесенням механізмів людського сприйняття на процеси обчислень.
Проте історія розчарувань та провалів тепер різко змінюється. Лише десять років тому алгоритми комп'ютерного зору та розпізнавання предметів могли ідентифікувати кулю або паралелепіпед на простому тлі. Тепер вони можуть розрізняти людські обличчя так само добре, як це можуть люди, навіть на складному, природному тлі. Півроку тому Google випустив додаток для смартфонів, здатний перекладати текст із більш ніж 20 іноземних мов, зчитуючи слова з фотографій, дорожніх знаків або рукописного тексту!
Все це стало можливим після того, як з'ясувалося, що деякі старі ідеї в галузі нейронних мереж, якщо їх трохи видозмінити, додавши «життя», тобто. спроектувавши деталі людського та тваринного сприйняття, можуть дати приголомшливий результат, на який ніхто і не очікував. На цей раз революція штучного розуму здається справді реальною.
Дослідження нейронних мереж у галузі машинного навчання у більшості випадків завжди були присвячені пошуку нових методик розпізнавання різних типів даних. Так, комп'ютер, підключений до камери, повинен, використовуючи алгоритм розпізнавання зображень, зуміти розрізнити картинці поганої якості людське обличчя, чашку чаю чи собаку. Історично, проте, використання нейронних мереж з цією метою супроводжувалося істотними труднощами. Навіть незначний успіх вимагав людського втручання – люди допомагали програмі визначити важливі особливості зображення, такі як межі зображення чи прості геометричні фігури. Існуючі алгоритми було неможливо самі навчитися робити це.
Стан справ різко змінився завдяки створенню так званих нейронних мереж із глибинним навчаннямякі тепер можуть проаналізувати зображення майже так само ефективно, як людина. Такі нейронні мережі використовують зображення поганої якості як вхідні дані для "нейронів" першого рівня, який потім передає "картинку" через нелінійні зв'язки нейронам наступного рівня. Після певного тренування, «нейрони» вищих рівнів можуть застосовувати для розпізнавання абстрактніші аспекти зображення. Наприклад, вони можуть використовувати такі деталі як межі зображення або особливості його розташування в просторі. Вражаюче, але такі мережі здатні навчитися оцінювати найважливіші особливості зображення без допомоги людини!
Чудовим прикладом використання нейронних мереж з глибинним навчанням є розпізнавання однакових об'єктів, сфотографованих під різними кутами або в різних позах (якщо йдеться про людину чи тварину). Алгоритми, що використовують попіксельне сканування, «думають», що перед ними два різні зображення, тоді як «розумні» нейронні мережі «розуміють», що перед ними той самий об'єкт. І навпаки - зображення двох собак різних порід, сфотографованих у однаковій позі, колишніми алгоритмами могли сприйматися як фотографії однієї й тієї собаки. Нейронні мережі з глибинним навчанням можуть виявити такі деталі зображень, які допоможуть розрізнити тварин.
Поєднання методик глибинного навчання, передових знань нейронауки та потужностей сучасних комп'ютерів відкриває для штучного інтелекту перспективи, які ми навіть не в змозі поки що оцінити. Щоправда, вже очевидно, що розум може мати не тільки біологічну природу.
Глибинне навчання змінює парадигму роботи з текстами, проте викликає скепсис у комп'ютерних лінгвістів та фахівців у галузі аналізу даних. Нейронні мережі – потужний, але тривіальний інструмент машинного навчання.
03.05.2017 Дмитро Ільвівський, Катерина Черняк
Нейронні мережі дозволяють знаходити приховані зв'язки та закономірності в текстах, але ці зв'язки не можуть бути представлені у явному вигляді. Нейронні мережі - хай і потужний, але досить тривіальний інструмент, що викликає скептицизм у компаній, що розробляють промислові рішення в галузі аналізу даних, та у провідних комп'ютерних лінгвістів.
Загальне захоплення нейромережевими технологіями та глибинним навчанням не обійшло стороною і комп'ютерну лінгвістику – автоматичну обробку текстів природною мовою. На недавніх конференціях асоціації комп'ютерної лінгвістики ACL, головному науковому форумі в цій галузі, переважна більшість доповідей була присвячена застосуванню нейронних мереж як для вирішення вже відомих завдань, так і для дослідження нових, які не вирішувалися за допомогою стандартних засобів машинного навчання. Підвищена увага лінгвістів до нейронних мереж обумовлена кількома причинами. Застосування нейронних мереж, по-перше, істотно підвищує якість вирішення деяких стандартних завдань класифікації текстів і послідовностей, по-друге, знижує трудомісткість при роботі безпосередньо з текстами, по-третє, дозволяє вирішувати нові завдання (наприклад, створювати чат-боти). У той самий час нейронні мережі не можна вважати цілком самостійним механізмом вирішення лінгвістичних проблем.
Перші роботи з глибинному навчанню(Deep learning) відносяться до середини XX століття. На початку 1940-х років Уоррен Маккаллок і Уолтер Піттс запропонували формальну модель людського мозку - штучну нейронну мережу, а трохи пізніше Френк Розенблатт узагальнив їхні роботи та створив модель нейронної мережі на комп'ютері. Перші роботи з навчання нейронних мереж з використанням алгоритму зворотного розповсюдження помилки належать до 1960-х років (алгоритм обчислює помилку передбачення та мінімізує її за допомогою методів стохастичної оптимізації). Однак виявилося, що, незважаючи на красу та витонченість ідеї імітації мозку, навчання «традиційних» нейронних мереж займає багато часу, а результати класифікації на невеликих наборах даних можна порівняти з результатами, отриманими більш простими методами, наприклад машинами опорних векторів (Support Vector Machine, SVM ). У результаті нейронні мережі були забуті на 40 років, але сьогодні знову стали затребувані при роботі з великими обсягами неструктурованих даних, зображень і текстів.
З формальної точки зору нейронна мережа є спрямованим графом заданої архітектури, вершини або вузли якого називаються нейронами. На першому рівні графа знаходяться вхідні вузли, на останньому – вихідні вузли, кількість яких залежить від завдання. Наприклад, для класифікації на два класи на вихідний рівень мережі можна помістити один або два нейрони, для класифікації на k класів - k нейронів. Решта всіх рівнів у графі нейронної мережі прийнято називати прихованими шарами. Всі нейрони, що знаходяться на одному рівні, пов'язані ребрами з усіма нейронами наступного рівня, кожне ребро має вагу. Кожному нейрону ставиться у відповідність функція активації, що моделює роботу біологічних нейронів: вони «мовчать», коли вхідний сигнал слабкий, а коли його значення перевищує якийсь поріг, спрацьовують і передають вхідне значення далі по мережі. Завдання навчання нейронної мережі на прикладах (тобто на парах «об'єкт - правильна відповідь») полягає в пошуку ваг ребер, які найкраще пророкують правильні відповіді. Зрозуміло, що саме архітектура – топологія будови графа нейронної мережі – є її найважливішим параметром. Хоча формального визначення для «глибинних мереж» поки немає, прийнято вважати глибинними всі нейронні мережі, що складаються з великої кількості шарів або мають «нестандартні» шари (наприклад, що містять лише обрані зв'язки або рекурсію з іншими шарами).
Прикладом найбільш успішного застосування нейронних мереж поки є аналіз зображень, проте нейромережевые технології докорінно змінили роботу з текстовими даними. Якщо раніше кожен елемент тексту (літера, слово чи речення) потрібно було описувати за допомогою безлічі ознак різної природи (морфологічних, синтаксичних, семантичних і т. д.), то тепер у багатьох завданнях необхідність складних описів пропадає. Теоретики та практики нейромережевих технологій часто говорять про «навчання уявленню» (representation learning) – у сирому тексті, розбитому тільки на слова та пропозиції, нейронна мережа здатна знайти залежності та закономірності та самостійно скласти ознаковий простір. На жаль, у такому просторі людина нічого не зрозуміє - під час навчання нейронна мережа ставить кожному елементу тексту у відповідність один щільний вектор, що складаються з деяких чисел, що становлять виявлені «глибинні» взаємозв'язки. Акцент при роботі з текстом зміщується від конструювання підмножини ознак та пошуку зовнішніх баз знань до вибору джерел даних та розмітки текстів для подальшого навчання нейронної мережі, для якого потрібно значно більше даних у порівнянні зі стандартними методами. Саме через необхідність використовувати великі обсяги даних і через слабку інтерпретованість і непередбачуваність нейронні мережі не затребувані в реальних додатках промислового масштабу, на відміну від інших алгоритмів навчання, що добре зарекомендували себе, таких як випадковий ліс і машини опорних векторів. Проте нейронні мережі використовуються в ряді завдань автоматичної обробки текстів (рис. 1).
Одне з найпопулярніших застосувань нейронних мереж - побудова векторів слів, що відносяться до галузі дистрибутивної семантики: вважається, що значення слова можна зрозуміти за значенням його контексту, за словами, що оточує. Дійсно, якщо нам незнайоме якесь слово в тексті відомою мовою, то в більшості випадків можна вгадати його значення. Математичною моделлю значення слова є вектори слів: рядки у великій матриці «слово-контекст», побудованої за досить великим корпусом текстів. Як «контекстів» для конкретного слова можуть виступати сусідні слова, слова, що входять з даними в одну синтаксичну або семантичну конструкцію, і т. д. У клітинах такої матриці можуть бути записані частоти (кілька разів слово зустрілося в даному контексті), але частіше використовують коефіцієнт позитивної попарної взаємної інформації (Positive Pointwise Mutual Information, PPMI), що показує, наскільки невипадковою була поява слова у тому чи іншому контексті. Такі матриці цілком успішно можуть бути використані для кластеризації слів або пошуку слів, близьких за змістом до шуканого слова.
У 2013 році Томаш Міколов опублікував роботу, в якій пропонував використовувати нейронні мережі для навчання векторам слів, але для меншої розмірності: за кортежами (слово, контексти) навчалася нейронна мережа найпростішої архітектури, на виході кожному слову у відповідність ставився вектор із 300 елементів. Виявилося, такі вектори краще передають семантичну близькість слів. Наприклад, на них можна визначити арифметичні операції додавання та віднімання смислів та отримати наступні рівняння: «Париж – Франція + Росія = Москва»; "король - чоловік + жінка = королева". Або знайти зайве слово у ряді «яблуко, груша, вишня, кошеня». У роботі були представлені дві архітектури, skip-gram та CBOW (Continuous Bag of Words), під загальною назвою word2vec. Як пізніше було показано в word2vec - це не що інше, як факторизація матриці «слово-контекст» з вагами PPMI. Зараз прийнято відносити word2vec до дистрибутивної семантики, а не до глибинного навчання, проте вихідним поштовхом для створення цієї моделі послужило застосування нейронної мережі. Крім того, виявилося, що вектора word2vec є зручним уявленням сенсу слова, яке можна подавати на вхід глибинним нейронним мережам, що використовуються для класифікації текстів.
Завдання класифікації текстів - одна з найактуальніших для маркетологів, особливо коли йдеться про аналіз думок чи ставлення споживача до якогось товару чи послуги, тому дослідники постійно працюють над підвищенням якості її вирішення. Однак аналіз думок є завданням класифікації скоріше речень, а не текстів - у позитивному відкликанні користувач може написати одну-дві негативно забарвлені пропозиції, і їх теж важливо вміти визначати та аналізувати. Відома складність у класифікації речень полягає у змінній довжині входу - оскільки речення у текстах бувають довільної довжини, незрозуміло, як подати їх на вхід нейронної мережі. Один із підходів запозичений в галузі аналізу зображень і полягає у використанні згорткових нейронних мереж (convolutional neural network, CNN) (рис. 2).
На вхід згорткової нейронної мережі подається речення, в якому кожне слово вже представлене вектором (вектор векторів). Як правило, для подання слів векторами використовуються заздалегідь навчені моделі word2vec. Згортка нейронна мережа складається з двох шарів: «глибинного» шару згортки і звичайного прихованого шару. Шар згортки, у свою чергу, складається з фільтрів та шару «субдискретизації». Фільтр - це нейрон, вхід якого формується за допомогою вікон, що пересуваються по тексту і вибирають послідовно деяку кількість слів (наприклад, вікно довжини «три» вибере перші три слова, слова з другого до четвертого, з третього по п'яте і т.д.) . На виході фільтра формується один вектор, що агрегує всі вектори слів, що до нього входять. Потім на шарі субдискретизації формується один вектор, відповідний всій пропозиції, який обчислюється як покомпонентний максимум всіх вихідних векторів фільтрів. Згорткові нейронні мережі прості у навчанні та реалізації. Для їх навчання використовується стандартний алгоритм зворотного поширення помилки, а за рахунок того, що ваги фільтрів рівномірно розподілені (вага i-го слова з вікна однакова для будь-якого фільтра), кількість параметрів у нейронній мережі згортки невелика. З погляду комп'ютерної лінгвістики згорткові нейронні мережі - потужний інструмент для класифікації, за яким, втім, не стоїть ніякої мовної інтуїції, що ускладнює аналіз помилок алгоритму.
Класифікація послідовностей - це завдання, у яких кожному слову потрібно поставити у відповідність одну мітку: морфологічний розбір (кожному слову ставиться у відповідність частина мови), вилучення іменованих сутностей (визначення того, чи є кожне слово частиною імені людини, географічної назви та ін.) і т. д. При класифікації послідовностей використовуються методи, що дозволяють враховувати контекст слова: якщо попереднє слово - частина імені людини, то поточне також може бути частиною імені, але навряд чи буде частиною назви організації. Реалізувати цю вимогу практично допомагають рекурентні нейронні мережі, що розширюють ідею мовних моделей (language model), запропонованих наприкінці минулого століття. Класична мовна модель передбачає ймовірність того, що слово i зустрінеться після слова i-1. Мовні моделі можна використовувати і для пророкування наступного слова: яке слово з найбільшою ймовірністю зустрінеться після цього?
Для навчання мовних моделей потрібні великі корпуси - що більше навчальний корпус, то більше пар слів модель «знає». Використання нейронних мереж для розробки мовних моделей дозволяє скоротити обсяг даних, що зберігаються. Уявімо просту архітектуру мережі, в якій на вхід надходять слова i-2 і i-1, а на виході нейронна мережа передбачає слово i. Залежно від числа прихованих шарів і кількості нейронів на них, навчена мережа може бути збережена як кілька щільних матриць відносно невеликої розмірності. Інакше кажучи, замість навчального корпусу та всіх пар слів у ньому можна зберігати лише кілька матриць та список унікальних слів. Однак, така нейронна мовна модель не дозволяє враховувати довгі зв'язки між словами. Цю проблему вирішують рекурентні нейронні мережі (рис. 3), у яких внутрішній стан прихованого шару як оновлюється після того, як на вхід приходить нове слово, а й передається на наступний крок. Таким чином, прихований шар рекурентної мережі приймає входи двох типів: стан прихованого шару на попередньому кроці та нове слово. Якщо рекурентна нейронна мережа обробляє пропозицію, то приховані стани дозволяють запам'ятовувати та передавати довгі зв'язки у реченнях. Експериментально неодноразово було перевірено, що рекурентні нейронні мережі запам'ятовують рід суб'єкта у реченні та обирають правильні займенники (вона – її, він – його) при генерації пропозиції, проте показати у явному вигляді, як саме такого роду інформація зберігається в нейронній мережі або як вона використовується , досі не вдалося.
Рекурентні нейронні мережі служать й у класифікації текстів. І тут виходи на проміжних кроках не використовуються, а останній вихід нейронної мережі повертає передбачений клас. Сьогодні двонаправлені (передаючі прихований стан не тільки «направо», а й «наліво») рекурентні мережі, що мають кілька десятків нейронів на прихованому шарі, стали стандартним інструментом для вирішення задач класифікації текстів та послідовностей, а також генерації текстів та по суті витіснили інші алгоритми .
Розвитком рекурентних нейронних мереж стали архітектури виду Seq2seq, що складаються з двох з'єднаних рекурентних мереж, одна з яких відповідає за подання та аналіз входу (наприклад, питання або пропозиції однією мовою), а друга - за генерацію виходу (відповіді або пропозиції іншою мовою) . Мережі Seq2seq лежать в основі сучасних систем «питання-відповідь», чат-ботів та систем машинного перекладу.
Крім згорткових нейронних мереж, для аналізу текстів застосовуються так звані автокодувальники, які використовуються, наприклад, для створення ефектів на зображеннях у Photoshop або Instagram і які знайшли застосування в лінгвістиці в задачі зниження розмірності (пошук проекції вектора, що представляє текст, на простір свідомо меншої розмірності). Проекція на двовимірне простір уможливлює уявлення тексту як точки на площині і дозволяє наочно зобразити колекцію текстів як безліч точок, тобто є засобом попереднього аналізу перед кластеризацією чи класифікацією текстів. На відміну від завдання класифікації, у задачі зниження розмірності немає чітких критеріїв якості, проте зображення, що отримуються під час використання автокодувальників, виглядають досить «переконливо». З математичної точки зору автокодувальник - це нейронна мережа без вчителя, яка навчається лінійної функції f(x) = x і складається з двох частин: кодувальника та декодувальника. Кодувальник - це мережа з декількома прихованими шарами зі зменшуваною кількістю нейронів. Декодувальник - аналогічна мережа з кількістю нейронів, що збільшується. Їх з'єднує прихований шар, на якому стільки нейронів, скільки має бути розмірностей у новому просторі меншої розмірності, і саме він відповідає за зниження розмірності. Як і згорткові нейронні мережі, автокодувальник не має жодної лінгвістичної інтерпретації, тому може вважатися швидше інженерним, ніж аналітичним інструментом.
Незважаючи на вражаючі результати, нейронна мережа не може вважатися самостійним інструментом для аналізу тексту (пошук закономірностей у мові) і тим більше для розуміння тексту. Так, нейронні мережі дозволяють знаходити приховані зв'язки між словами та виявляти закономірності в текстах, але поки ці зв'язки не представлені в інтерпретованому вигляді, нейронні мережі залишатимуться досить тривіальними інструментами машинного навчання. Крім того, у промислових аналітичних рішеннях глибинне навчання поки що не затребуване, оскільки потребує невиправданих витрат на підготовку даних за непередбачуваності результатів. Навіть у дослідницькому співтоваристві висловлюється критичне ставлення до спроб зробити нейронні мережі універсальним інструментом. У 2015 році Кріс Маннінг, голова групи комп'ютерної лінгвістики в Стенфорді і президент ACL, чітко окреслив коло застосування нейронних мереж. У нього він включив завдання класифікації текстів, класифікації послідовностей та зниження розмірності. Однак завдяки маркетингу та популяризації глибинного навчання зросла увага власне до комп'ютерної лінгвістики та її нових додатків.
Дмитро Ільвівський ([email protected]) - співробітник Міжнародної лабораторії інтелектуальних систем та структурного аналізу, Катерина Черняк ([email protected]) – викладач центру безперервної освіти, факультет комп'ютерних наук, НДУ ВШЕ (Москва). Роботу виконано у рамках Програми фундаментальних досліджень НДУ ВШЕ.
»(Manning Publications).
Стаття розрахована на людей, які вже мають значний досвід роботи з глибинним навчанням (наприклад, тих, хто вже прочитав розділи 1-8 цієї книги). Передбачається наявність великої кількості знань.
Весь процес застосування цієї складної геометричної трансформації на вхідних даних можна візуалізувати в 3D, зобразивши людину, яка намагається розгорнути паперовий м'ячик: зім'ята паперова грудочка - це різноманіття вхідних даних, з якими модель починає роботу. Кожен рух людини з паперовим м'ячиком схожий на просту геометричну трансформацію, яку виконує один шар. Повна послідовність жестів розгортання - це складна трансформація всієї моделі. Моделі глибинного навчання - це математичні машини з розгортання заплутаного різноманіття багатовимірних даних.
Ось у чому магія глибинного навчання: перетворити значення на вектори, на геометричні простори, а потім поступово навчатися складним геометричним перетворенням, які перетворюють один простір на інший. Все, що потрібно - це простору досить великої розмірності, щоб передати весь спектр відносин, знайдених у вихідних даних.
Причина в тому, що модель глибинного навчання – це «лише» ланцюжок простих, безперервних геометричних перетворень, які перетворюють один векторний простір на інший. Все, що вона може, це перетворити одну множину даних X на іншу множину Y, за умови наявності можливої безперервної трансформації з X в Y, якій можна навчитися, і доступності щільного набору зразківперетворення X:Y як даних на навчання. Отже, хоча модель глибинного навчання можна вважати різновидом програми, але більшість програм не можна виразити як моделі глибинного навчання- для більшості завдань або не існує глибинної нейромережі практично відповідного розміру, яка вирішує завдання, або якщо існує, вона може бути ненавчена, тобто відповідне геометричне перетворення може бути занадто складним, чи ні відповідних даних щодо її навчання.
Масштабування існуючих технік глибинного навчання - додавання більшої кількості шарів та використання більшого обсягу даних для навчання - здатне лише поверхнево пом'якшити деякі з цих проблем. Воно не вирішить фундаментальнішу проблему, що моделі глибинного навчання дуже обмежені в тому, що вони можуть представляти, і що більшість програм не можна висловити у вигляді безперервного геометричного морфінгу різноманіття даних.
Зокрема, найяскравіше це проявляється у «змагальних прикладах», тобто зразках вхідних даних мережі глибинного навчання, спеціально підібраних, щоб їх неправильно класифікували. Ви вже знаєте, що можна зробити градієнтне сходження у просторі вхідних даних для генерації зразків, які максимізують активацію, наприклад, певного фільтра згорткової нейромережі – це основа техніки візуалізації, яку ми розглядали у розділі 5 (примітка: книги «Глибинне навчання з Python») , також як алгоритму Deep Dream з глави 8. Схожим способом, через градієнтне сходження, можна трохи змінити зображення, щоб максимізувати передбачення класу для заданого класу. Якщо взяти фотографію панди та додати градієнт «гіббон», ми можемо змусити нейромережу класифікувати цю панду як гіббона. Це свідчить як про крихкість цих моделей, так і про глибоку різницю між трансформацією зі входу на вихід, якою вона керується, та нашим власним людським сприйняттям.

Загалом у моделей глибинного навчання немає розуміння вхідних даних, принаймні не в людському розумінні. Наше власне розуміння зображень, звуків, мови, засноване на сенсомоторному досвіді як людей - як матеріальних земних істот. У моделей машинного навчання немає доступу до такого досвіду і тому вони не можуть «зрозуміти» наші вхідні дані будь-яким людиноподібним способом. Анотуючи для наших моделей велику кількість прикладів для навчання, ми змушуємо їх вивчити геометричне перетворення, яке наводить дані до людських концепцій для цього специфічного набору прикладів, але це перетворення є лише спрощеним начерком оригінальної моделі нашого розуму, яке розроблене виходячи з нашого досвіду як тілесних агентів – це як слабке відображення у дзеркалі.

Як практикуючий спеціаліст з машинного навчання, завжди пам'ятайте про це, і ніколи не потрапляйте в пастку віри в те, що нейромережі розуміють завдання, яке виконують - вони не розуміють, принаймні не таким чином, який має сенс для нас. Вони були навчені іншій, набагато вужчій задачі, ніж та, якій ми хочемо їх навчити: простого перетворення вхідних зразків навчання на цільові зразки навчання, точка до точки. Покажіть їм щось, що відрізняється від даних навчання, і вони зламаються абсурдним способом.
Люди здатні набагато більше, ніж перетворення негайного стимулу в негайний відгук, як нейромережа чи, можливо, комаха. Люди утримують у свідомості складні, абстрактні моделі поточної ситуації, самих себе, інших людей, і можуть використовувати ці моделі для передбачення різних можливих варіантів майбутнього та виконувати довготривале планування. Вони здатні на об'єднання в єдине ціле відомих концепцій, щоб уявити те, що вони ніколи не знали раніше - як малювання коня в джинсах, наприклад, або зображення того, що вони зробили, якби виграли в лотерею. Здатність мислити гіпотетично, розширювати свою модель ментального простору далеко за межі того, що ми безпосередньо відчували, тобто здатність робити абстракціїі міркування, мабуть, визначальна характеристика людського пізнання Я називаю це "граничним узагальненням": здатність пристосовуватися до нових, ніколи не випробуваних раніше ситуацій, використовуючи дуже мало даних або зовсім не використовуючи жодних даних.
Це різко відрізняється від того, що роблять мережі глибинного навчання, що я б назвав «локальним узагальненням»: перетворення вхідних даних у вихідні дані швидко припиняє мати сенс, якщо нові вхідні дані хоч трохи відрізняються від того, з чим вони зустрічалися під час навчання . Розглянемо, наприклад, проблему навчання відповідним параметрам запуску ракети, яка має сісти на Місяць. Якби ви використовували нейромережу для цього завдання, навчаючи її з учителем або з підкріпленням, вам знадобилося б дати їй тисячі чи мільйони траєкторій польоту, тобто потрібно видати щільний набір прикладіву просторі вхідних значень, щоб навчитися надійному перетворенню з простору вхідних значень у простір вихідних значень. На відміну від них, люди можуть використовувати силу абстракції для створення фізичних моделей – ракетобудування – і вивести точне рішення, яке доставить ракету на Місяць лише за кілька спроб. Таким же чином, якщо ви розробили нейромережу для керування людським тілом і хочете, щоб вона навчилася безпечно проходити містом, не будучи збитою автомобілем, мережа повинна померти багато тисяч разів у різних ситуаціях, перш ніж зробить висновок, що автомобілі небезпечні, і не виробить відповідну поведінку, щоб їх уникати. Якщо її перенести в нове місто, то мережі доведеться знову вчитися більшій частині того, що вона знала. З іншого боку, люди здатні вивчити безпечну поведінку, не померши жодного разу - знову завдяки силі абстрактного моделювання гіпотетичних ситуацій.

Отже, незважаючи на наш прогрес у машинному сприйнятті, ми все ще дуже далекі від ІІ людського рівня: наші моделі можуть виконувати лише локальне узагальнення, адаптуючись до нових ситуацій, які мають бути дуже близькими до минулих даних, в той час як людський розум здатний на граничне узагальненняшвидко пристосовуючись до абсолютно нових ситуацій або плануючи далеко в майбутнє.
Щоб зняти деякі з цих обмежень та почати конкурувати з людським мозком, нам потрібно відійти від прямого перетворення з входу у вихід та перейти до міркуваннямі абстракцій. Можливо, підходящою основою для абстрактного моделювання різних ситуацій та концепцій можуть бути комп'ютерні програми. Ми говорили раніше (примітка: у книзі «Глибинне навчання з Python»), що моделі машинного навчання можна визначити як «програми, що навчаються»; в даний момент ми можемо навчати лише вузьке та специфічне підмножина всіх можливих програм. Але що якби ми могли навчати кожну програму, модульно та багаторазово? Подивимося, як ми можемо прийти до цього.
На високому рівні ось основні напрямки, які я вважаю перспективними:
Отже, вперед.
Як цього досягти? Візьмемо добре відомий тип мережі RNN. Що важливо, у RNN трохи менше обмежень, ніж у нейромереж прямого поширення. Це тому що RNN є трохи більше, ніж прості геометричні перетворення: це геометричні перетворення, які здійснюються безперервно в циклі for. Тимчасовий цикл for задається розробником: це вбудоване припущення мережі. Природно, мережі RNN все ще обмежені в тому, що вони можуть представляти, в основному, тому що кожен їх крок, як і раніше, є геометричним перетворенням, що диференціюється, і через спосіб, яким вони передають інформацію крок за кроком через точки в безперервному геометричному просторі ( вектори стану). Тепер уявіть нейромережі, які б «нарощувалися» примітивами програмування таким же способом, як цикли for – але не просто одним-єдиним жорстко закодованим циклом for з прошитою геометричною пам'яттю, а великим набором примітивів програмування, з якими модель могла б вільно поводитися для розширення своїх можливостей обробки, таких як гілки if , оператори while , створення змінних, дискове сховище для довгострокової пам'яті, оператори сортування, просунуті структури даних на кшталт списків, графів, хеш-таблиць та багато іншого. Простір програм, які така мережа може представляти, буде набагато ширшим, ніж можуть виразити існуючі мережі глибинного навчання, і деякі з цих програм можуть досягти чудової сили узагальнення.
Одним словом, ми уникнемо того, що у нас з одного боку є «жорстко закодований алгоритмічний інтелект» (написане вручну ПЗ), а з іншого боку - «навчений геометричний інтелект» (глибинне навчання). Натомість ми отримаємо суміш формальних алгоритмічних модулів, які забезпечують можливості міркуваньі абстракції, та геометричні модулі, які забезпечують можливості неформальної інтуїції та розпізнавання шаблонів. Вся система цілком буде навчена з невеликою людською участю або без неї.
Споріднена область ІІ, яка, на мою думку, скоро може сильно просунутися, це програмний синтеззокрема, нейронний програмний синтез. Програмний синтез полягає в автоматичній генерації простих програм, використовуючи пошуковий алгоритм (можливо генетичний пошук, як у генетичному програмуванні) для вивчення великого простору можливих програм. Пошук зупиняється, коли знайдено програму, що відповідає необхідним специфікаціям, які часто надаються як набір пар вхід-вихід. Як бачите, це сильно нагадує машинне навчання: «дані навчання» надаються як пари вхід-вихід, ми знаходимо «програму», яка відповідає трансформації вхідних у вихідні дані та здатна до узагальнення нових вхідних даних. Різниця в тому, що замість значень параметрів навчання у жорстко закодованій програмі (нейронній мережі) ми генеруємо вихідний кодшляхом дискретного пошукового процесу.
Я певно очікую, що до цієї області знову прокинеться великий інтерес у наступні кілька років. Зокрема, я чекаю на взаємне проникнення суміжних областей глибинного навчання та програмного синтезу, де ми будемо не просто генерувати програми мовами загального призначення, а де ми генеруватимемо нейромережі (потоки обробки геометричних даних), доповненібагатим набором алгоритмічних примітивів, таких як цикли for - та багато інших. Це має бути набагато зручніше і корисніше, ніж пряма генерація вихідного коду, і суттєво розширить межі для тих проблем, які можна вирішувати за допомогою машинного навчання – простір програм, які ми можемо генерувати автоматично, отримуючи відповідні дані для навчання. Суміш символічного ІІ та геометричного ІІ. Сучасні RNN можна як історичного предка таких гібридних алгоритмо-геометрических моделей.

Малюнок: Навчена програма одночасно покладається на геометричні примітиви (розпізнавання шаблонів, інтуїція) та алгоритмічні примітиви (аргументація, пошук, пам'ять).
Крім того, зворотне розповсюдження має рамки end-to-end, що підходить для навчання хороших зчеплених перетворень, але досить неефективне з обчислювальної точки зору, тому що повністю не використовує модульність глибинних мереж. Щоб підвищити ефективність будь-чого, є один універсальний рецепт: ввести модульність та ієрархію. Тож ми можемо зробити саме зворотне поширення ефективнішим, ввівши розчеплені модулі навчання з певним механізмом синхронізації між ними, організованому в ієрархічному порядку. Ця стратегія частково відображена в недавній роботі DeepMind щодо «синтетичних градієнтів». Я чекаю набагато, набагато більше робіт у цьому напрямку у найближчому майбутньому.
Можна уявити майбутнє, де глобально недиференційовані моделі (але з наявністю частин, що диференціюються) будуть навчатися - зростати - з використанням ефективного пошукового процесу, який не застосовуватиме градієнти, в той час як диференційовані частини будуть навчатися навіть швидше, використовуючи градієнти з використанням якоїсь більш ефективної версії зворотного розповсюдження
Зараз більшу частину часу розробник систем глибинного навчання нескінченно модифікує дані скриптами Python, потім довго налаштовує архітектуру та гіперпараметри мережі глибинного навчання, щоб отримати працюючу модель - або навіть отримати видатну модель, якщо розробник настільки амбітний. Нема чого й казати, що це не найкращий стан речей. Але ІІ і тут може допомогти. На жаль, частину обробки та підготовки даних важко автоматизувати, оскільки вона часто вимагає знання області, а також чіткого розуміння на високому рівні, чого розробник хоче досягти. Однак налаштування гіперпараметрів – це проста пошукова процедура, і в даному випадку ми вже знаємо, чого хоче досягти розробник: це визначається функцією втрат нейромережі, яку потрібно налаштувати. Зараз вже стало звичайною практикою встановлювати базові системи AutoML, які беруть на себе велику частину підкрутки налаштувань моделі. Я й сам установив таку, щоб виграти змагання Kaggle.
На самому базовому рівні така система буде просто налаштовувати кількість шарів у стеку, їх порядок та кількість елементів чи фільтрів у кожному шарі. Це зазвичай робиться за допомогою бібліотек на кшталт Hyperopt, які ми обговорювали у розділі 7 (примітка: книги «Глибинне навчання з Python»). Але можна піти набагато далі та спробувати отримати навчанням відповідну архітектуру з нуля, з мінімальним набором обмежень. Це можливо за допомогою навчання із підкріпленням, наприклад, або за допомогою генетичних алгоритмів.
Іншим важливим напрямком розвитку AutoML є отримання навчання архітектури моделі одночасно з вагами моделі. Навчальна модель з нуля щоразу ми пробуємо трохи різні архітектури, що надзвичайно неефективно, тому дійсно потужна система AutoML керуватиме розвитком архітектур, у той час як властивості моделі налаштовуються через зворотне розповсюдження на даних для навчання, таким чином усуваючи надмірність обчислень. Коли я пишу ці рядки, такі підходи вже почали застосовувати.
Коли все це почне відбуватися, розробники систем машинного навчання не залишаться без роботи - вони перейдуть на вищий рівень у ланцюжку створення цінностей. Вони почнуть прикладати набагато більше зусиль до створення складних функцій втрат, які по-справжньому відображають ділові завдання, і будуть глибоко розумітися на тому, як їх моделі впливають на цифрові екосистеми, в яких вони працюють (наприклад, клієнти, які користуються прогнозами моделі та генерують дані для її навчання) - проблеми, які зараз можуть дозволити собі розглядати лише найбільші компанії.
До того ж, останніми роками неодноразово звучало чудове спостереження, що навчання однієї й тієї моделі робити кілька слабо пов'язаних завдань покращує її результати у кожному з цих завдань. Наприклад, навчання однієї і тієї ж нейромережі перекладати з англійської на німецьку та з французької на італійську призведе до отримання моделі, яка буде кращою у кожній з цих мовних пар. Навчання моделі класифікації зображень одночасно з моделлю сегментації зображень, з єдиною згортковою базою, призведе до отримання моделі, яка краща в обох задачах. І так далі. Це цілком інтуїтивно зрозуміло: завжди є якасьінформація, яка частково збігається між цими двома на перший погляд різними завданнями, і тому загальна модель має доступ до більшої кількості інформації про кожну окрему задачу, ніж модель, яка навчалася тільки на цій конкретній задачі.
Що ми робимо насправді, коли повторно застосовуємо модель на різних завданнях, так це використовуємо ваги для моделей, які виконують загальні функції, на кшталт отримання візуальних ознак. Ви бачили це на практиці в розділі 5. Я очікую, що в майбутньому буде повсюдно використовуватися загальніша версія цієї техніки: ми не тільки будемо застосовувати раніше засвоєні ознаки (ваги підмоделі), але також архітектури моделей та процедури навчання. У міру того, як моделі стануть схожими на програми, ми почнемо повторно використовувати підпрограми, як функції та класи у звичайних мовах програмування.
Подумайте, як виглядає сьогодні процес розробки програмного забезпечення: як тільки інженер вирішує певну проблему (HTTP-запити в Python, наприклад), він пакує її як абстрактну бібліотеку для повторного використання. Інженери, яким у майбутньому зустрінеться схожа проблема, просто шукають існуючі бібліотеки, завантажують та використовують їх у своїх власних проектах. Так само в майбутньому системи метанавчання зможуть збирати нові програми, просіюючи глобальну бібліотеку високорівневих блоків, що повторно використовуються. Якщо система почне розробляти схожі підпрограми для кількох різних завдань, то випустить «абстрактну» версію підпрограми, що повторно використовується, і збереже її в глобальній бібліотеці. Такий процес відкриє можливість для абстракції, необхідного компонента для досягнення «граничного узагальнення»: підпрограма, яка виявиться корисною для багатьох завдань та областей, можна сказати, «абстрагує» певний аспект прийняття рішень. Таке визначення абстракції схоже не поняття абстракції в розробці програмного забезпечення. Ці підпрограми можуть бути або геометричними (модулі глибинного навчання з передбаченими уявленнями) або алгоритмічними (ближче до бібліотек, з якими працюють сучасні програмісти).

Малюнок: Метаобучаемая система, здатна швидко розробити специфічні завдання моделі із застосуванням повторно використовуваних примітивів (алгоритмічних і геометричних), рахунок цього досягаючи «граничного узагальнення».
Сьогодні граф – один із найприйнятніших способів описати моделі, створені в системі машинного навчання. Ці обчислювальні графіки складені з вершин-нейронів, з'єднаних ребрами-синапсами, що описують зв'язки між вершинами.
На відміну від скалярного центрального або векторного графічного процесора, IPU – новий тип процесорів, спроектований для машинного навчання, дозволяє будувати такі графи. Комп'ютер, який призначений для керування графами, - ідеальна машина для обчислювальних моделей графів, створених у рамках машинного навчання.
Один із найпростіших способів, щоб описати процес роботи машинного інтелекту – це візуалізувати його. Команда розробників Graphcore створила колекцію таких зображень, що відображаються на IPU. В основу лягло програмне забезпечення Poplar, що візуалізує роботу штучного інтелекту. Дослідники з цієї компанії також з'ясували, чому глибокі мережі потребують так багато пам'яті і які шляхи вирішення проблеми існують.
Poplar включає графічний компілятор, який був створений з нуля для перекладу стандартних операцій, що використовуються в рамках машинного навчання у високооптимізований код додатків для IPU. Він дозволяє зібрати ці графи разом за тим же принципом, як збираються POPNN. Бібліотека містить набір різних типів вершин для узагальнених примітивів.
Графи – це парадигма, де грунтується все програмне забезпечення. У Poplar графи дозволяють визначити процес обчислення, де вершини виконують операції, а ребра описують зв'язок між ними. Наприклад, якщо ви хочете скласти два числа разом, ви можете визначити вершину з двома входами (числа, які ви хотіли б скласти), деякі обчислення (функція складання двох чисел) і вихід (результат).

Зазвичай операції з вершинами набагато складніше, ніж у наведеному вище прикладі. Найчастіше вони визначаються невеликими програмами, які називаються коделетами (кодовими іменами). Графічна абстракція є привабливою, оскільки не робить припущень про структуру обчислень і розбиває обчислення на компоненти, які процесор IPU може використовувати для роботи.
Poplar застосовує цю просту абстракцію для побудови великих графів, які представлені у вигляді зображення. Програмна генерація графіка означає, що ми можемо адаптувати його до конкретних обчислень, необхідних для забезпечення ефективного використання ресурсів IPU.
Компілятор переводить стандартні операції, що використовуються в машинних системах навчання, високооптимізований код програми для IPU. Компілятор графів створює проміжне зображення обчислювального графа, яке розгортається однією чи кількох пристроях IPU. Компілятор може відображати цей обчислювальний граф, тому програма, написана на рівні структури нейронної мережі, відображає зображення обчислювального графа, який виконується на IPU.

Граф повного циклу навчання AlexNet у прямому та зворотному напрямку
Графічний компілятор Poplar перетворив опис AlexNet на обчислювальний граф з 18,7 мільйона вершин і 115,8 мільйона ребер. Чітко видима кластеризація – результат міцного зв'язку між процесами у кожному шарі мережі з легшим зв'язком між рівнями.
Інший приклад - проста мережа з повним зв'язком, що пройшла навчання на MNIST - простому наборі даних для комп'ютерного зору, свого роду Hello, world в машинному навчанні. Проста мережа вивчення цього набору даних допомагає зрозуміти графи, якими керують програми Poplar. Інтегруючи бібліотеки графів з такими середовищами, як TensorFlow, компанія представляє один із простих шляхів для використання IPU у програмах машинного навчання.

Після того, як за допомогою компілятора збудувався граф, його потрібно виконати. Це можливо за допомогою двигуна Graph Engine. На прикладі ResNet-50 демонструється його робота.

Граф ResNet-50
Архітектура ResNet-50 дозволяє створювати глибокі мережі з розділів, що повторюються. Процесор залишається лише один раз визначити ці розділи і повторно викликати їх. Наприклад, кластер рівня conv4 виконується шість разів, але лише один раз наноситься на граф. Зображення також демонструє різноманітність форм згорткових шарів, оскільки кожен із них має граф, побудований відповідно до природної форми обчислення.
Двигун створює та керує виконанням моделі машинного навчання, використовуючи граф, створений компілятором. Після розгортання Graph Engine контролює та реагує на IPU або пристрої, що використовуються програмами.
Зображення ResNet-50 показує всю модель. На цьому рівні складно виділити зв'язок між окремими вершинами, тому варто подивитися на збільшені зображення. Нижче наведено кілька прикладів секцій усередині шарів нейромережі.


Архітектури були розроблені з використанням процесорних мікросхем, призначених для послідовної обробки та оптимізації DRAM для високощільної пам'яті. Інтерфейс між цими двома пристроями є вузьким місцем, яке вводить обмеження пропускної здатності і додає значні накладні витрати в споживанні енергії.
Хоча ми ще не маємо повного уявлення про людський мозок і про те, як він працює, загалом зрозуміло, що немає великого окремого сховища пам'яті. Вважається, що функція довготривалої та короткочасної пам'яті у людському мозку вбудована у структуру нейронів+синапсів. Навіть прості організми на кшталт черв'яків з нейронною структурою мозку, що складається з трохи більше 300 нейронів, певною мірою функцією пам'яті.
Побудова пам'яті в звичайних процесорах - це один із способів обійти проблему вузьких місць пам'яті, відкривши величезну пропускну здатність при значно меншому споживанні енергії. Тим не менш, пам'ять на кристалі – дорога штука, яка не розрахована на дійсно великі обсяги пам'яті, які підключені до центральних та графічних процесорів, які нині використовуються для підготовки та розгортання глибинних нейронних мереж.
Тому корисно подивитися на те, як пам'ять сьогодні використовується в центральних процесорах і системах глибокого навчання на графічних прискорювачах, і запитати себе: чому їм необхідні такі великі пристрої зберігання пам'яті, коли головний мозок людини відмінно працює без них?
Нейронним мережам потрібна пам'ять для того, щоб зберігати вхідні дані, вагові параметри та функції активації, як вхід поширюється через мережу. У навчанні активація на вході повинна зберігатись доти, доки її не можна буде використовувати, щоб обчислити похибки градієнтів на виході.
Наприклад, 50-шарова мережа ResNet має близько 26 мільйонів вагових параметрів та обчислює 16 мільйонів активацій у прямому напрямку. Якщо ви використовуєте 32-бітове число з плаваючою комою для зберігання кожної ваги та активації, то для цього потрібно близько 168 Мб простору. Використовуючи більш низьке значення точності для зберігання цих ваг та активацій, ми могли б вдвічі чи навіть вчетверо знизити цю вимогу для зберігання.
Серйозна проблема з пам'яттю виникає через те, що графічні процесори покладаються дані, які у вигляді щільних векторів. Тому вони можуть використовувати одиночний потік команд (SIMD) для досягнення високої густини обчислень. Центральний процесор використовує аналогічні векторні блоки високопродуктивних обчислень.
У графічних процесорах ширина синапсу становить 1024 біт, так що вони використовують 32-бітові дані з плаваючою комою, тому часто розбивають їх на паралельно працюючі mini-batch із 32 зразків для створення векторів даних по 1024 біт. Цей підхід до організації векторного паралелізму збільшує кількість активацій у 32 рази та потреба у локальному сховищі ємністю понад 2 ГБ.
Графічні процесори та інші машини, призначені для матричної алгебри, також піддаються навантаженню на згадку з боку ваги або активації нейронної мережі. Графічні процесори не можуть ефективно виконувати невеликі пакунки, що використовуються у глибоких нейронних мережах. Тому перетворення, зване «зниженням», використовується для перетворення цих згорток на матрично-матричні множення (GEMM), з якими графічні прискорювачі можуть ефективно справлятися.
Додаткова пам'ять також потрібна для зберігання вхідних даних, тимчасових значень та інструкцій програми. Вимір використання пам'яті при навчанні ResNet-50 на високопродуктивному графічному процесорі показало, що їй потрібно більше 7,5 ГБ локальної DRAM.
Можливо, хтось вирішить, що нижча точність обчислень може скоротити необхідний обсяг пам'яті, але це негаразд. При перемиканні значень даних до половинної точності для ваги та активацій ви заповните лише половину векторної ширини SIMD, витративши половину наявних обчислювальних ресурсів. Щоб компенсувати це, коли ви перемикаєтеся з повної точності до половини точності на графічному процесорі, тоді доведеться подвоїти розмір mini-batch, щоб викликати достатній паралелізм даних для всіх доступних обчислень. Таким чином, перехід на більш низьку точність ваги та активації на графічному процесорі все ще вимагає більше 7,5ГБ динамічної пам'яті з вільним доступом.
З такою великою кількістю даних, які потрібно зберігати, помістити все це у графічному процесорі просто неможливо. На кожному шарі згорткової нейронної мережі необхідно зберегти стан зовнішньої DRAM, завантажити наступний шар мережі та завантажити дані в систему. В результаті, вже обмежений пропускною здатністю затримкою пам'яті інтерфейс зовнішньої пам'яті страждає від додаткового тягаря постійного перезавантаження ваг, а також збереження та вилучення функцій активації. Це значно уповільнює час навчання та значно збільшує споживання енергії.
Існує кілька шляхів вирішення цієї проблеми. По-перше, такі операції, як функції активації можуть виконуватися “на місцях”, дозволяючи перезаписувати вхідні дані безпосередньо на виході. Таким чином, існуючу пам'ять можна використовувати повторно. По-друге, можливість повторного використання пам'яті можна отримати, проаналізувавши залежність даних між операціями в мережі і розподілом тієї ж пам'яті для операцій, які не використовують її в цей момент.
Другий підхід особливо ефективний, коли вся нейронна мережа може бути проаналізована на етапі компіляції, щоб створити фіксовану виділену пам'ять, оскільки витрати на керування пам'яттю скорочуються майже до нуля. З'ясувалося, що комбінація цих методів дозволяє скоротити використання пам'яті нейронною мережею вдвічі-втричі.
Третій значний підхід нещодавно був виявлений командою Baidu Deep Speech. Вони застосували різні методи збереження пам'яті, щоб отримати 16-кратне скорочення споживання пам'яті функціями активації, що дозволило їм навчати мережі зі 100 шарами. Раніше при тому ж об'ємі вони могли навчати мережі з дев'ятьма шарами.
Об'єднання ресурсів пам'яті та обробки в одному пристрої має значний потенціал для підвищення продуктивності та ефективності згорткових нейронних мереж, а також інших форм машинного навчання. Можна зробити компроміс між пам'яттю та обчислювальними ресурсами, щоб досягти балансу можливостей та продуктивності в системі.
Нейронні мережі та моделі знань в інших методах машинного навчання можна як математичні графи. У цих графах зосереджено дуже багато паралелізму. Паралельний процесор, призначений для використання паралелізму в графах, не покладається на mini-batch і може значно зменшити обсяг локального сховища.
Сучасні результати досліджень показали, що ці методи можуть значно поліпшити продуктивність нейронних мереж. Сучасні графічні та центральні процесори мають дуже обмежену вбудовану пам'ять, лише кілька мегабайт у сукупності. Нові архітектури процесорів, спеціально розроблені для машинного навчання, забезпечують баланс між пам'яттю та обчисленнями на чіпі, забезпечуючи суттєве підвищення продуктивності та ефективності в порівнянні з сучасними центральними процесорами та графічними прискорювачами.
Про штучні нейронні мережі сьогодні багато говорять і пишуть – як у контексті великих даних і машинного навчання, так і поза ним. У цій статті ми нагадаємо сенс цього поняття, ще раз окреслимо сферу його застосування, а також розповімо про важливий підхід, який асоціюється з нейронними мережами – глибоке навчання, опишемо його концепцію, а також переваги та недоліки у конкретних випадках використання.
Як відомо, поняття нейронної мережі (НС) прийшло з біології і є дещо спрощеною моделлю будови людського мозку. Але не будемо заглиблюватися в природничі нетрі - найпростіше уявити нейрон (у тому числі, штучний) як якийсь чорний ящик з безліччю вхідних отворів і одним вихідним.
Математично, штучний нейрон здійснює перетворення вектора вхідних сигналів (впливів) X вектор вихідних сигналів Y за допомогою функції, званої функцією активації. У рамках з'єднання (штучної нейронної мережі - ІНС) функціонують три види нейронів: вхідні (приймають інформацію із зовнішнього світу - значення змінних, що цікавлять нас), вихідні (повертають шукані змінні - наприклад, прогнози, або керуючі сигнали), а також проміжні - нейрони , виконують деякі внутрішні («приховані») функції. Класична ІНС, таким чином, складається з трьох або більше шарів нейронів, причому на другому та наступних шарах («прихованих» та вихідному) кожен з елементів з'єднаний з усіма елементами попереднього шару.
Важливо пам'ятати про поняття зворотного зв'язку, яке визначає вид структури ІНС: прямої передачі сигналу (сигнали йдуть послідовно від вхідного шару через прихований і надходять у вихідний шар) і рекурентної структури, коли мережа містить зв'язки, що йдуть назад, від дальніх до ближніх нейронів ). Всі ці поняття становлять необхідний мінімум інформації для переходу на наступний рівень розуміння ІНС – навчання нейронної мережі, класифікації його методів та розуміння принципів роботи кожного з них.
Не слід забувати, для чого взагалі використовуються подібні категорії – інакше є ризик ув'язнути у абстрактній математиці. Насправді під штучними нейронними мережами розуміють клас методів для вирішення певних практичних завдань, серед яких головними є завдання розпізнавання образів, прийняття рішень, апроксимації та стиснення даних, а також найцікавіші для нас завдання кластерного аналізу та прогнозування.
Не йдучи в іншу крайність і не вдаючись у подробиці роботи методів ІНС у кожному конкретному випадку, дозволимо собі нагадати, що за будь-яких обставин саме здатність нейронної мережі до навчання (з учителем чи «самостійно») і є ключовим моментом використання її для вирішення практичних завдань .
У загальному випадку навчання ІНС полягає в наступному:
Такий загальний алгоритм навчання нейронної мережі (згадаймо собаку Павлова – так-так, внутрішній механізм утворення умовного рефлексу саме такий – і тут же забудемо: все ж таки наш контекст передбачає оперування технічними поняттями та прикладами).
Зрозуміло, що універсального алгоритму навчання немає і, швидше за все, існувати неспроможна; концептуально підходи до навчання поділяються на навчання з учителем та навчання без учителя. Перший алгоритм передбачає, що для кожного вхідного («навчається») вектора існує необхідне значення вихідного («цільового») вектора – таким чином, ці два значення утворюють навчальну пару, а вся сукупність таких пар – навчальна множина. У разі варіанти навчання без вчителя навчальна множина складається лише з вхідних векторів – і така ситуація є правдоподібнішою з погляду реального життя.
Поняття глибокого навчання (deep learning) відноситься до іншої класифікації та позначає підхід до навчання так званих глибоких структур, до яких можна віднести багаторівневі нейронні мережі. Простий приклад з області розпізнавання образів: необхідно навчити машину виділяти все більш абстрактні ознаки в термінах інших абстрактних ознак, тобто визначити залежність між виразом всього обличчя, очей і рота і, зрештою, скупчення кольорових пікселів математично. Таким чином, у глибокій нейронній мережі за кожний рівень ознак відповідає свій шар; Відомо, що з навчання такої «махини» необхідний відповідний досвід дослідників і рівень апаратного забезпечення. Умови склалися на користь глибокого навчання СР лише до 2006 року – і через вісім років можна говорити про революцію, яку зробив цей підхід у машинному навчанні.
Отже, передусім у контексті нашої статті варто зауважити наступне: глибоке навчання в більшості випадків не контролюється людиною. Тобто, цей підхід передбачає навчання нейронної мережі без вчителя. Це і є головна перевага «глибокого» підходу: машинне навчання з учителем, особливо у разі глибоких структур, потребує колосальних тимчасових та трудових витрат. Глибоке ж навчання - підхід, що моделює людське абстрактне мислення (або, принаймні, є спробою наблизитися до нього), а не використовує його.
Ідея, як водиться, прекрасна, але на шляху підходу постають цілком природні проблеми - перш за все, що кореняться в його претензії на універсальність. Насправді, якщо на терені розпізнавання образів підходи deep learning досягли відчутних успіхів, то з тією ж обробкою природної мови виникає поки що набагато більше питань, ніж відповідей. Очевидно, що у найближчі n років навряд чи вдасться створити «штучного Леонардо Да Вінчі» чи навіть – хоч би! - "Штучного homo sapiens".
Тим не менш, перед дослідниками штучного інтелекту вже постає питання етики: побоювання, що висловлюються в кожному науково-фантастичному фільмі, що поважає себе, починаючи з «Термінатора» і закінчуючи «Трансформерами», вже не здаються смішними (сучасні витончені нейромережі вже цілком можуть вважатися правдоподібною моделлю роботи мозку комахи!), але поки що явно зайві.
Ідеальне техногенне майбутнє видається нам як ера, коли людина зможе делегувати машині більшість своїх повноважень - або хоча б дозволити їй полегшити істотну частину своєї інтелектуальної роботи. Концепція глибокого навчання – один із кроків на шляху до цієї мрії. Шлях має бути довгий - але вже зараз зрозуміло, що нейронні мережі і пов'язані з ними всі підходи, що розвиваються, здатні з часом втілити в життя сподівання наукових фантастів.

У 2018 році Різдвяний пост розпочнеться 28 листопада. У цей період православні віруючі готуються до зустрічі Різдва.

Створення сім'ї – мрія більшості жінок. Вони хочуть мати люблячого чоловіка і купу дітей. Тільки от не завжди стосунки...

Ця стаття містить: найсильніша молитва від розлучення - інформація взята зі всіх куточків світла, електронної мережі та...

Інформаційний сайт про ікони, молитви, православні традиції. Молитва від скандалів та сварок у сім'ї, з чоловіком, з дітьми...

Який же Новий рік без шампанського, мандарин, «Олів'є», заливного та всіма улюбленої «Оселедця під шубою». Ось із останнім...

Підготуємо необхідні інгредієнти для печива. Перше, що потрібно зробити - це поставити воду кип'ятитися. Нам необхідний...

Чи можна оформити працівника посаду фінансовий директор - головний бухгалтер. Головний бухгалтер стверджує, що...

Керівник невеликого бізнесу може вести бюджет самостійно. ПЕРЕВІРЕНО! Якщо займатися веденням...

Створення нових проектів передбачає попереднє економічне обґрунтування їхньої доцільності, наступне...
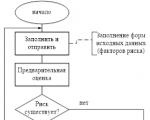
Звітність формується РМ, проходить узгодження (схвалення) Комітету з ризиків за Правління та передається на...

На краю великого луга, на довгій смарагдовій травинці жила крихітна Божа Корівка. Маленька Божа...

Нині досить поширене звернення людини до зірок. За допомогою гороскопу людина може дізнатися...

Діловий чи приятельський. Якщо ж переслідували незнайомку - значить рівень вашої довіри до жіночої статі.

по соннику ФрейдаЯкщо вам снилося, як ви ловили рибу, значить, у реальному житті ви насилу можете відключитися...

Створення сім'ї – мрія більшості жінок. Вони хочуть мати люблячого чоловіка і купу дітей. Тільки от не завжди...

Ця стаття містить: найсильніша молитва від розлучення - інформація взята зі всіх куточків світла, електронної...