Шпанська Мушка для двох – як впливають на лібідо у жінок та чоловіків
Біологічно активна добавка на основі екстракту, отриманого з жука шпанкою мушки (або шпанки...)
Що таке семантичне ядро сайту? Семантичне ядро сайту (далі за текстом СЯ) - це сукупність ключових слів і фраз, за якими ресурс просуваєтьсяу пошукових системах та які свідчать про належність сайту до певної тематиці.
Для успішного просування в пошукових системах, ключові слова повинні бути правильно згруповані і розподілені на сторінках сайту і в певному вигляді містяться в мета-описах (, , keywords), а також у заголовках H1-H6. При цьому, не можна допускати переспаму, щоб не "полетіти" в .
У цій статті ми постараємося поглянути на питання не лише з технічного погляду, а й подивитися на проблему очима власників бізнесу та маркетологів.
Отже, докладніше розглянемо кожен пункт із різними прикладами.
На першому кроці важливо визначити, які товари та послуги, присутні на сайті, просуватимуться в пошуковій видачі Яндекса та Google.
Приклад №1.Допустимо на сайті є два напрямки послуг: ремонт комп'ютерів вдома та навчання роботі з Word/Exel вдома. В даному випадку було прийнято рішення, що навчання вже не має попиту, тому його немає сенсу просувати, а значить і збирати по ньому семантику. Ще один важливий момент, потрібно збирати не лише запити, що містять «ремонт комп'ютерів на дому», але і ремонт ноутбуків, ремонт ПКта інші.
Приклад №2.Компанія займається малоповерховим будівництвом. Але при цьому будує лише дерев'яні будинки. Відповідно, запити та семантику за напрямками «Будівництво будинків з газобетону»або «будівництво будинків із цегли»можна не збирати.
Ми розглянемо два основні джерела ключових слів: Яндекс та Google. Розкажемо, як зібрати семантику безкоштовно і коротко побачимо платні сервіси, що дозволяють прискорити та автоматизувати цей процес.
В Яндексі збір ключових фраз здійснюється з сервісу Яндекс.Вордстат та в Гуглі через статистику запитів у Google AdWords. При наявності як додаткових джерел семантики можна використовувати дані Яндекс Вебмайстер і Яндекс Метрики, Google Вебмайстер і Google Analytics.
Збір запитів з Вордстат можна вважати безкоштовним. Для перегляду даних цього сервісу вам знадобиться лише обліковий запис в Яндексі. Отже, заходимо на wordstat.yandex.ruта вводимо ключове слово. Розглянемо приклад збору семантики для сайту компанії з прокату авто.

Що ми бачимо на цьому скріншоті?
Перевіряйте різні варіанти ключових фраз і отримані дані фіксуйте у таблиці Exel або таблицях Google. Для зручності встановіть плагін Yandex Wordstat Helper.Після його встановлення поруч із пошуковими фразами з'являться плюсики, при натисканні на який слова копіюватиметься, не потрібно буде виділяти та вставляти показник частотності вручну.
На жаль Google не має відкритого джерела пошукових запитів з їх показниками частотності, тому тут потрібно діяти обхідними шляхами. І для цього нам знадобиться робочий обліковий запис у Google AdWords.
Реєструємо обліковий запис в Google AdWords і поповнюємо баланс на мінімально можливу суму - 300 рублів (на неактивному в плані бюджету обліковому записі, відображаються приблизні дані). Після цього заходимо до «Інструментів» — «Планувальник ключових слів».

Відкриється нова сторінка, де у вкладці «Пошук нових ключових слів за фразою, сайтом або категорією» введіть ключовик.

Скролимо вниз, натискаємо «Отримати варіанти» і бачимо приблизно таку картину.

Ми розглянули роботу з двома основними джерелами статистики пошукових запитів. Тепер перейдемо до автоматизації цього процесу, тому що збирання семантики вручну займає надто багато часу.
Програма встановлюється на комп'ютер. У програмі підключаються робочі облікові записи від куди буде збиратися статистика. Далі створюється новий проект та папка для ключових слів.
Вибираємо "Пакетний збір слів з лівої колонки Yandex.Wordstat", вводимо запити, за якими збираємо дані.

На скріншоті введено приклад, насправді для повнішого СЯ, тут додатково потрібно зібрати всі варіанти запитів з марками автомобілів та класами. Наприклад, "bmw на прокат", "купити Toyota з правом викупу", "оренда позашляховика" і так далі.
Безкоштовний аналогпопередньої програми. Це можна вважати як плюсом — не потрібно платити, так і мінусом — програма значно урізає функціонал.
Для збору ключових слів, дії самі.
Онлайн сервіс. Його основна перевага – не потрібно нічого завантажувати та встановлювати. Зареєструйся та користуйся. Сервіс платний, але при реєстрації на вашому рахунку є 200 монет, чого вистачить, щоб зібрати невелику семантику (до 5000 запитів) і спарсити частотність.
Мінус - збір семантики тільки з Wordstat.

І знову зауважуємо зменшення кількості запитів. Ідемо далі і спробуємо іншу словоформу того самого запиту.

Зазначаємо, що в однині, цей запит шукає набагато меншу кількість користувачів, отже початковий запит для нас є більш пріоритетним.
Такі маніпуляції необхідно провести з кожним словом та словосполученням. Ті запити, якими підсумкова частотність виявляється рівної нулю (при використанні лапок і знака оклику), відсіюються, т.к. "0" - говорить про те, що такі запити ніхто не вводить і ці запити є лише частиною інших. Сенс складання семантичного ядра полягає в тому, щоб відібрати запити, які використовують люди для пошуку. Всі запити потім розміщуються в таблиці Exel, групуються за змістом і розподіляються на сторінках сайту.

Вручну це зробити просто не реально, тому в інтернеті існує безліч сервісів, платних та безкоштовних, які дозволяють зробити це автоматично. Наведемо кілька:
Після просівання ключовиків слід видалити непотрібні. Які пошукові запити можна видаляти зі списку?
Суть цього етапу - об'єднати схожі за змістом запити в кластери, а потім визначити, на які сторінки вони будуть просуватися. Як зрозуміти які запити просувати на одну сторінку, а які на іншу?
1. За типом запиту.
Нам уже відомо, що всі діляться на кілька видів, залежно від мети пошуку:
Якщо ви сумніваєтеся, до якого типу відноситься запит, введіть його рядок пошуку і проаналізуйте видачу. За комерційним запитом буде більше сторінок із пропозицією послуг, за інформаційним — статей.
Також є . Більшість комерційних запитів є геозалежними, оскільки люди більшою мірою довіряють компаніям, які перебувають у їхньому місті.
2. Логіка запиту.
Переглянути пошукову видачу за ними. Якщо перевірити, на які сторінки у різних сайтів ведуть запити «будівництво будинків із бруса» та «будівництво будинків з цегли», то в 99% випадків це різні сторінки.
4. Автоматичне угруповання за допомогою ПЗ та ручне доопрацювання.
Перший і другий методи добре підходять для складання семантичного ядра маленьких веб-сайтів, де зібрано максимум 2-3 тисячі ключових слів. Для великого СЯ (від 10000 до безкінечності запитів), потрібна допомога машин. Ось кілька програм та сервісів, які дозволяють виконувати кластеризацію:
Після завершення автоматичної кластеризації необхідно перевірити результат робіт програми в ручну і якщо допущені помилки — виправляти.
Приклад:програма може відправити в один кластер наступні запити: «відпочинок у сочі 2018 готель» та «відпочинок у сочі 2018 готель бриз» — у першому випадку користувач шукає різні варіанти готелів для проживання, а в другому конкретний готель.
Щоб унеможливити виникнення подібних неточностей, потрібно вручну все перевіряти і при виявленні помилок, правити.
На основі зібраного семантичного ядра, далі ми:
Виглядає це приблизно так.

Під кожен сформований кластер запиту ми створюємо сторінку на сайті та визначаємо йому місце у структурі сайту. Найбільш популярні запити, що просуваються на найвищі сторінки в ієрархії ресурсу, менш популярні розташовуються під ними.
І для кожної з цих сторінок, у нас вже зібрані запити, які ми просуватимемо на них. Далі пишемо ТЗ копірайтерам, щоб зробити текст цих сторінок.
Як і у випадку зі структурою сайту, опишемо цей етап загалом. Отже, технічне завдання на текст:
Пам'ятайте не треба намагатися просувати на одну сторінку +100 500 запитів, обмежтеся 5-10 + хвіст, інакше отримаєте бан за переоптимізацію і надовго вилетите з гри за місця в ТОПі.
Висновок
Складання семантичного ядра сайту - копітка і важка праця, якій потрібно приділити особливо пильну увагу, тому що саме на ньому базується подальше просування сайту. Дотримуйтесь простої інструкції, наведеної в цій статті та дійте.
Семантичне ядро - це страшна назва, яку придумали SEOшники для позначення досить простої речі. Нам треба просто підібрати ключові запити, за якими ми просуватимемо наш сайт.
І в цій статті я покажу вам, як правильно скласти семантичне ядро, щоб ваш сайт швидше вийшов у ТОП, а не тупцював місяцями на місці. Тут також є свої «секретики».
І перш ніж ми перейдемо до складання СЯ, давайте розберемо, що це таке, і до чого ми зрештою маємо прийти.
Як це не дивно, але семантичне ядро - це звичайний excel файл, в якому списком представлені ключові запити, за якими ви (або копірайтер) писатимете статті для сайту.
Ось як, наприклад, виглядає моє семантичне ядро:
Зеленим кольором у мене позначені ключові запити, за якими я вже написав статті. Жовтим – ті, яким статті збираюся написати найближчим часом. А безбарвні осередки — це означає, що до цих запитів справа дійде трохи згодом.
Для кожного ключового запиту в мене визначена частотність, конкурентність, і придуманий заголовок, що «чіпляє». Ось приблизно такий самий файл має вийти і у вас. Зараз у мене СЯ складається із 150 ключовиків. Це означає, що я забезпечений «матеріалом» мінімум на 5 місяців наперед (якщо навіть писатиму за однією статтею на день).
Трохи нижче ми поговоримо про те, до чого вам готуватися, якщо раптом вирішите замовити збір семантичного ядра у фахівців. Тут скажу коротко — вам дадуть такий самий список, але лише на тисячі «ключів». Однак, у СЯ важлива не кількість, а якість. І ми з вами орієнтуватимемося саме на це.
А справді, навіщо нам ці муки? Можна ж, зрештою, просто так писати якісні статті, і залучати цим аудиторію правильно? Так, писати можна, а от залучати не вийде.
Головна помилка 90% блогерів - це саме написання просто якісних статей. Я не жартую, у них реально цікаві та корисні матеріали. Ось тільки пошукові системи про це не знають. Вони ж не екстрасенси, а лише роботи. Відповідно, вони і не ставлять вашу статтю в ТОП.
Тут є ще один тонкий момент із заголовком. Наприклад, у вас є дуже якісна стаття на тему «Як правильно вести бізнес у «Мордокнизі». Там ви дуже докладно та професійно розписуєте все про фейсбук. У тому числі й те, як там просувати спільноти. Ваша стаття – найякісніша, корисна та цікава в інтернеті на цю тему. Ніхто й поряд із вами не валявся. Але це вам все одно не допоможе.
Уявіть, що на ваш сайт зайшов не робот, а живий перевіряльник (асесор) з Яндекса. Він зрозумів, що у вас найкласніша стаття. І рукам поставив вас на перше місце у видачі на запит «Просування спільноти у фейсбук».
Знаєте, що станеться далі? Ви звідти все одно швидко вилетите. Тому що за вашою статтею, навіть на першому місці, ніхто не кликатиме. Люди вводять запит «Просування спільноти до фейсбуку», а у вас заголовок — «Як правильно вести бізнес у «мордокнизі». Оригінально, свіжо, кумедно, але не під запит. Люди хочуть бачити саме те, що вони шукали, а чи не ваш креатив.
Відповідно, ваша стаття вхолосту займатиме місце в ТОП видачі. І живий асесор, гарячий шанувальник вашої творчості, може скільки завгодно благати начальство залишити вас хоча б у ТОП-10. Але не поможе. Усі перші місця займуть порожні, як лушпиння від насіння, статейки, які одне в одного переписали вчорашні школярі.
Натомість ці статті мають правильний «релевантний» заголовок — «Просування спільноти у фейсбук з нуля» ( за кроками, за 5 кроків, від А до Я, безкоштовнота ін) Прикро? Ще б. Ну, так боріться проти несправедливості. Давайте складемо грамотне семантичне ядро, щоб ваші статті займали перші заслужені місця.
Є ще одна річ, про яку чомусь люди мало замислюються. Вам треба писати статті часто - як мінімум щотижня, а краще 2-3 рази на тиждень, щоб набрати більше трафіку і швидше.
Усі це знають, але майже ніхто цього не робить. А все тому, що у них «творчий застій», «не можуть себе змусити», «просто ліньки». А насправді вся проблема саме у відсутності конкретного семантичного ядра.
Я ввів у поле пошуку один зі своїх базових ключів — «smm», і Яндекс відразу видав мені з десяток підказок, що ще може бути цікаво людям, яким цікаво «smm». Мені залишається лише скопіювати ці ключі до блокнотика. Потім я так само перевірю кожен з них, і зберу підказки ще й по них.
Після першого етапу збору СЯ у вас має вийти текстовий документ, у якому буде 10-30 широких базових ключів, з якими ми працюватимемо далі.
Звичайно, якщо ви напишіть статтю під запит "вебінар" або "smm", то дива не станеться. Ви ніколи не зможете вийти в ТОП за таким широким запитом. Нам треба розбити базовий ключ на безліч дрібних запитів на цю тему. І робити це ми за допомогою спеціальної програми.
Я використовую KeyCollector, але це платний. Ви можете скористатися безкоштовним аналогом – програмою SlovoEB. Завантажити її можна з офіційного сайту.
Найскладніше у роботі з цією програмою – це її правильно налаштувати. Як правильно налаштувати і використовувати Слово я показую. Але в тій статті я наголошую на доборі ключів для Яндекс-Директа.
А тут давайте по кроках подивимося особливості використання цієї програми для складання семантичного ядра під SEO.
Спочатку створюємо новий проект, і називаємо його за тим широким ключем, який хочете парсити.
Я зазвичай даю таку назву проекту, як і мій базовий ключ, щоб потім не заплутатися. Так, попереджу вас ще від однієї помилки. Не намагайтеся парсить усі базові ключі одночасно. Вам потім буде дуже складно відфільтрувати "порожні" ключові запити від золотих крупинок. Давайте ширяти по одному ключу.
Після створення проекту – проводимо базову операцію. Тобто ми, власне, паримо ключ через Яндекс Вордстат. Для цього натисніть кнопку «Ворстат» в інтерфейсі програми, впишіть ваш базовий ключ і натисніть «Почати збір».
Для прикладу, давайте розпаримо базовий ключ для мого блогу «контекстна реклама».
Після цього запуститься процес, і через деякий час програма нам дасть результат — до 2000 ключових запитів, які містять «контекстну рекламу».
Також поруч із кожним запитом стоятиме «брудна» частотність — скільки разів цей ключ (+ його словоформи і хвости) шукали за місяць через яндекс. Але не раджу робити жодних висновків із цих цифр.
Брудна частотність нам нічого не покаже. Якщо ви орієнтуватиметеся на неї, то не дивуйтеся потім, коли ваш ключ на 1000 запитів не приносить жодного кліка на місяць.
Нам треба виявити чисту частотність. І для цього ми спочатку виділяємо всі знайдені ключі галочками, а потім натискаємо на кнопку «Яндекс Директ» і знову запускаємо процес. Тепер Слово буде нам шукати точну частоту запиту на місяць для кожного ключа.
Тепер у нас є об'єктивна картина — скільки разів запит вводили користувачі інтернету за останній місяць. Пропоную тепер згрупувати всі ключові запити щодо частотності, щоб з ними було зручніше працювати.
Для цього натискаємо на значок "фільтр" у стовпці "Частота "!" », і вказуємо - відфільтрувати ключі зі значенням «менше або 10».
Тепер програма покаже вам ті запити, частотність яких менша або дорівнює значенню «10». Ці запити можна видалити або скопіювати на майбутнє до іншої групи ключових запитів. Менше 10 – це дуже мало. Писати статті під ці запити — марнування часу.
Зараз нам треба вибрати ті ключові запити, які принесуть нам більш менш хороший трафік. І для цього нам треба з'ясувати ще один параметр – рівень конкурентності запиту.
Усі «ключі» у світі діляться на 3 типу: високочастотні (ВЧ), среднечастотные (СЧ), низкочастотные (НЧ). А ще вони можуть бути висококонкурентними (ВК), середньоконкурентними (СК) та низькоконкурентними (НК).
Як правило, ВЧ запити є одночасно і ВК. Тобто якщо запит часто шукають в інтернеті, то й сайтів, які хочуть просуватися по ньому — дуже багато. Але це не завжди так, бувають щасливі винятки.
Мистецтво складання семантичного ядра таки полягає у тому, щоб знайти такі запити, які мають високу частотність, а рівень конкуренції у них низький. Вручну визначити рівень конкуренції дуже складно.
Можна орієнтуватися на такі показники, як кількість головних сторінок у ТОП-10, довжина та якість текстів. рівень трасту та тиц сайтів у ТОП видачі за запитом. Все це дасть вам деяке уявлення про те, як жорстка боротьба за позиції для цього конкретного запиту.
Але я рекомендую вам скористатися сервісом Мутаген. Він зважає на всі парметри, про які я сказав вище, плюс ще з десяток, про які ні ви, ні я напевно навіть не чули. Після аналізу сервіс видає точне значення - який рівень конкуренції у цього запиту.
Тут я перевірив запит налаштування контекстної реклами в google adwords. Мутаген показав нам, що цей ключ має конкурентність «понад 25» — це максимальне значення, яке він показує. А переглядів цього запиту всього 11 на місяць. Значить, нам він точно не підходить.
Ми можемо скопіювати всі ключі, які підібрали до Словоєба, і зробити масову перевірку в Мутаген. Після цього нам залишиться лише переглянути список та взяти ті запити, які мають багато запитів та низький рівень конкуренції.
Мутаген – це платний сервіс. Але 10 перевірок за добу ви можете зробити безкоштовно. Крім того, вартість перевірки дуже низька. За весь час роботи з ним я ще не витратив 300 рублів.
До речі, щодо рівня конкуренції. Якщо у вас молодий сайт, краще вибирати запити з рівнем конкуренції 3-5. А якщо ви розкручуєтесь вже понад рік, то можна брати і 10-15.
До речі, щодо частотності запитів. Нам зараз треба зробити заключний крок, який дозволить вам залучати чимало трафіку навіть за низькочастотними запитами.
Як уже багато разів було доведено та перевірено, основний обсяг трафіку ваш сайт отримуватиме не від основних ключів, а від так званих хвістів. Це коли людина вводить у пошуковий рядок дивні ключові запити з частотністю 1-2 на місяць, але таких запитів дуже багато.
Щоб побачити хвіст — просто зайдіть в Яндекс і введіть обраний вами ключовий запит у рядок пошуку. Ось що ви приблизно побачите.
Тепер вам потрібно просто виписати ці додаткові слова в окремий документ і використовувати їх у своїй статті. При чому не треба ставити їх завжди поряд із основним ключем. Інакше пошукові системи побачать переоптимізацію і ваші статті впадуть у видачі.
Просто використовуйте їх у різних місцях вашої статті, і тоді ви отримуватимете додатковий трафік ще й за ними. Ще б я вам рекомендував постаратися використовувати якомога більше словоформ та синонімів для вашого основного ключового запиту.
Наприклад, ми маємо запит — «Налаштування контекстної реклами». Ось як можна його переформулювати:
Ніколи не знаєш, як саме люди шукатимуть інформацію. Додайте всі ці додаткові слова до себе в семантичне ядро та використовуйте при написанні текстів.
Ось так, ми збираємо список зі 100 - 150 ключових запитів. Якщо ви складаєте семантичне ядро вперше, то у вас може піти кілька тижнів.
А може, ну його, очі ламати? Може є можливість делегувати складання СЯ фахівцям, які зроблять це краще та швидше? Так, такі фахівці є, але користуватись їхніми послугами потрібно не завжди.
За великим рахунком фахівці зі складання семантичного ядра зроблять вам тільки кроки 1-3 з нашої схеми. Іноді, за велику додаткову плату, зроблять і кроки 4-5 (збір хвостів і перевірку конкурентності запитів).
Після цього вони видадуть вам кілька тисяч ключових запитів, з якими вам треба буде працювати далі.
І питання тут у тому, чи збираєтеся ви писати статті самостійно, чи наймете для цього копірайтерів. Якщо ви хочете наголошувати на якості, а не на кількості — то треба писати самим. Але тоді вам буде недостатньо просто отримати перелік ключів. Вам треба буде вибрати ті теми, в яких ви знаєтеся досить добре, щоб написати якісну статтю.
І ось тут постає питання — а навіщо тоді власне потрібні фахівці з СЯ? Погодьтеся, розпарити базовий ключ і зібрати точні частотності (кроки #1-3) - це зовсім не складно. У вас піде на це майже півгодини часу.
Найскладніше — саме обрати ВЧ запити, які мають низьку конкуренцію. А тепер ще, як з'ясовується, треба ВЧ-НК, на які ви можете написати гарну статтю. Саме це займе у вас 99% часу роботи над семантичним ядром. І цього вам не зробить жоден фахівець. Ну і чи варто витрачатися на замовлення таких послуг?
Інша річ, якщо ви спочатку плануєте залучати копірайтерів. Тоді вам необов'язково розумітися на темі запиту. Копірайтери ваші теж не розбиратимуться в ній. Вони просто візьмуть кілька статей на цю тему, і скомпілюють із них «свій» текст.
Такі статті будуть порожніми, убогими, майже марними. Але їх буде багато. Самостійно ви зможете писати максимум 2-3 якісні статті на тиждень. А армія копірайтерів забезпечить вам 2-3 говнотексти на день. При цьому вони будуть оптимізовані під запити, а значить залучатимуть якийсь трафік.
У цьому випадку — так, спокійно наймайте фахівців із СЯ. Нехай вони вам ще й ТЗ для копірайтерів складуть заразом. Але самі розумієте, це теж коштуватиме окремих грошей.
Давайте ще раз пробіжимося за основними думками у статті для закріплення інформації.
Сподіваюся, ця інструкція була вам корисною. Зберігайте її у вибране, щоб не втратити, та поділіться з друзями. Не забудьте завантажити мою книгу. Там я показую вам найшвидший шлях з нуля до першого мільйона в інтернеті (вичавка з особистого досвіду за 10 років =)
До скорого!
Ваш Дмитро Новосьолов
Здрастуйте, шановні читачі!
Часто при особистих розмовах з веб-майстрами бачу нерозуміння важливості ключових слів для пошуку. Тому я вирішив написати окрему посаду на цю важливу тему. Що таке семантичне ядро сайту, його плюси та мінуси, приклад готового ядра, поради щодо його правильного складання — тема цієї статті. Ви дізнаєтеся, чому в плані seo-просування такі важливі для веб-ресурсу правильно підібрані ключові слова. Відчуєте їхню важливість та винятковість, побачите силу від їх використання.Чому я написав цей пост? По-перше, моя стаття призначена для веб-майстрів-початківців, які тільки почали розбиратися в сео просуванні. І по-друге, в топ-20 в Яндексі немає жодної статті, яка б докладно розкрила користувачеві з пошуку суть семантичного ядра. Виправимо цей недолік. Сподіваюся, російська пошукова система це зарахує. 🙂
Кожен із нас вміє користуватися телефонним довідником. Чи то кишеньковий алфавітний варіант у вигляді записника або великий друкований талмуд усіх телефонів міста — принцип його використання дуже простий. Ми шукаємо за певним прізвищем усі контактні дані шуканої людини. Для цього нам треба знати повністю ПІБ людини. Зазвичай, знаючи прізвище людини, ми можемо легко подивитися в довіднику всі записи і вибрати потрібне. Тобто, знаючи певне слово (прізвище), ми можемо отримати всі дані щодо людини, які записані у книжці.

За таким принципом і працює семантика сайту — ми в пошуковій системі набираємо пошуковий запит (аналог того прізвища, контакти для якого шукаємо в довіднику) і отримуємо список документів, що найбільш точно відповідають на нього, з різних веб-ресурсів. Ці документи є окремими сторінками сайтів або блогів, контент на яких оптимізований під запитуваний нами запит, який називається ключовим словом. Таким чином, звичайне семантичне ядро є набором пошукових запитів (ключових слів), які характеризують тематику веб-ресурсу, вид його діяльності (зазвичай для комерційних сайтів, які пропонують послуги або товари в мережі Інтернет).

Тому семантичне ядро виконує дуже важливу функцію - воно дозволяє веб-ресурсу отримати на свої сторінки користувачів пошукових систем, які необхідні для виконання різних завдань. Наприклад, для комерційного сайту такими завданнями може бути продаж товарів чи послуг, для порталу новин — рекламування сторонніх джерел за допомогою контекстної чи банерної реклами, для блогу — рекламування партнерських програм тощо. Тобто ядро є саме тим фундаментом, який необхідний для отримання пошукового трафіку за допомогою seo просування. Без правильного та якісного набору ключових слів отримати такий трафік не реально.
Тому, якщо ми хочемо використовувати ресурси та можливості пошукових систем для розкручування свого веб-ресурсу, йому потрібно мати грамотне семантичне ядро. Якщо ж ми не хочемо отримувати пошуковий трафік, якщо нам не потрібна цільова аудиторія з пошуку, наявність семантики для нашого сайту не обґрунтована. Ключові слова нам не потрібні.
У пошуковому просуванні існує основне та другорядне семантичне ядро. Основне передбачає набір головних ключових слів, за допомогою яких даний сайт реалізує поставлені перед ним цілі та завдання. Наприклад, це можуть бути пошукові запити, за якими переходять з пошуку потенційні покупці товарів або послуг на комерційному сайті. Тобто, завдяки запитам основного ядра сайт або блог виконують своє призначення. Саме за такими ключовими словами йде перетворення звичайного користувача з пошуку в клієнта.
Другорядне семантичне ядро дозволяє веб-ресурсу вирішити менш значущі завдання або отримати додатковий трафік для залучення більшої кількості потенційних клієнтів. У такому разі спектр ключових слів може бути не лише основною тематикою сайту, а й суміжних тем. Зазвичай використовується в ряді комерційних сайтів, які хочуть конвертувати відвідувачів за допомогою додаткових статей для продажу послуг або товарів на сторінках, що продають. Наприклад, так роблять багато сайтів, що надають seo-послуги. На їх веб-ресурсах крім основних сторінок, що продають і пояснюють, існує додатковий великий набір документів, які разом утворюють варіант блогу.

У блогерів основним ядром є список ключових слів, які приносять йому пошуковий трафік, оскільки він є основним завданням при монетизації блогу за допомогою цільової аудиторії з пошуку. А другорядної семантики зазвичай блог не має. Тому що яке б не було завдання у блогу, весь трафік по всіх сторінках, що просуваються в пошукових системах, йде на вирішення його комерційного завдання. Але, зазвичай, ключові слова з основної тематики дають набагато більше комерційних переходів, ніж ключі непрофільної теми.
Ключові слова для семантичного ядра вибираються за різними параметрами (частотність, конкурентність тощо). Про це я докладно написав у . Залежно від цих параметрів підбираються семантичні ядра для комерційних сайтів, для блогів, для порталів новин і т.д. Вибір тих чи інших значень цих характеристик залежить від трьох складових - від стратегії просування, від кількості виділеного на нього бюджету та тематики сфери діяльності сайту, що просувається.
Стратегія просування диктує план підбору ключових слів, акцентуючи свою увагу на взаємозв'язок сторінок з сайтом, що просуваються, і їх якість. По-перше, тут важлива схема перелінкування сторінок - від її правильного вибору залежить число і важливість документів, які будуть просуватися в пошукових системах. Для кожного веб-ресурсу схема повинна бути своя, за допомогою якої буде кращий розподіл ваги на документи, що розкручуються. По-друге, необхідно знати обсяг контенту сторінки, що просувається (для якого підбираються ключові слова) — залежно від кількості символів використовується те чи інше число ключових ключів для неї.
Від кількості бюджету залежить можливість використання у семантичному ядрі конкурентних запитів. Чим більше коштів може веб-майстер виділити на свій проект, тим кращі слова він може включити до його семантики. Адже не секрет, що найякісніші розкручені ключовики завжди коштують пристойних грошей за влучення в топ-10 за ними. Отже для просування сторінок за цими ключовими запитами недостатньо внутрішньої оптимізації — необхідна закупівля зовнішніх посилань, потрібні матеріальні ресурси для їх закупівлі.
Від тематики залежить насамперед мінімальний поріг частотності ключового слова, який можна використовуватиме отримання пошукового трафіку. Чим конкурентніша тематика і чим вона вже (в плані її популярності), тим більше свій погляд веб-майстер кидає у бік низько-і мікрочастотних слів (частотність їх менше 50-100 залежно від тематики). Наприклад, тема мого блогу (seo та веб-аналітика) дуже вузька і більше ключових слів я не зможу використовувати для створення семантичного ядра. Тому більша частина ключових слів мого блогу - це пошукові запити НЧ і МК з частотністю не більше 100. Якщо порівняти з популярними темами (наприклад, кулінарія - НЧ запити в ній доходять до 1000!), то можна легко зрозуміти, що отримати серйозний трафік по дрібній темі дуже важко - потрібно мати величезну кількість ключових слів маленької частотності (зате не конкурентної). А отже потрібно мати величезну кількість сторінок, що просуваються.

Щоб створити семантичне ядро, необхідно виконати низку послідовних дій:
Після того, як повне семантичне ядро сайту створено, у плані просування настав час братися за внутрішню оптимізацію сторінок і потім робити ефективну перелінковку.
Для того щоб Ви могли побачити готовий результат, я вирішив викласти шматочок замовленого у мене семантичного ядра. На цьому скріншоті Ви побачите таблицю підібраних ключових слів (картинка клікабельна) :

Як бачите, всі ключові слова розподілені за статтями (розподіл здійснює замовник самостійно або за окрему плату). Відразу видно, які пошукові запити з таблиці можуть бути головним запитом, які у вигляді додаткових ключовиков. Все це дозволяє замовнику не заважаючи впроваджувати отримані ключові слова одразу в готові пости або робити приблизний план майбутніх постів — чітко і зрозуміло видно.
Якщо ви бажаєте зібрати повноцінне семантичне ядро для комерційного сайту або інформаційного проекту, рекомендую звернутися.
Як і в будь-якій справі, створення семантичного ядра має свої позитивні та негативні сторони. Спочатку поговоримо про мінуси:
Як бачите, мінусів небагато, але вони суттєві. І якщо матеріальні засоби не такі важливі, то вивчення потрібного матеріалу потребує часу, який цінуватиметься найбільше. Адже його не можна повернути… Перейдемо до плюсів:

І насамкінець найважливіша порада. Не женіться за великими і товстими ключовими ключами. Не буде від цього користі, тільки проблем собі назбираєте, витративши море часу марно. Беріть в обіг мій наступний трифазний принцип підбору ключових слів, який я успішно використовую на своєму блозі (понад 80% ключових слів знаходяться в топ-30, близько 49% в топ-10 в Яндексі і більше 20% в Google - і це в моїй складній конкурентній тематиці!):
Перед початком seo просування потрібно скласти семантичне ядро сайту - список пошукових запитів, який використовують при пошуку товарів, що ми пропонуємо, або потенційних клієнтів. Всі подальші роботи — внутрішня оптимізація та робота із зовнішніми факторами (купівля посилань) ведуться відповідно до визначеного на цьому етапі списку запитів.
Від правильного збору ядра також залежить підсумкова вартість просування і навіть передбачуваний рівень конверсії (кількість звернень до компанії).
Чим більша кількість компаній просувається за обраним словом, тим вища конкуренція і відповідно вартість просування.
Також при виборі списку запитів слід не тільки покладатися на свої уявлення про те, які слова використовують ваші потенційні клієнти, але й довіряти думці професіоналів, адже далеко не всі дорогі і популярні запити мають високу конверсію і просування деяких з слів, що безпосередньо відносяться до вашого бізнесу. бути просто невигідним, навіть за можливості досягти ідеального результату у вигляді ТОП-1.
Правильно сформоване семантичне ядро, за інших рівних, забезпечує впевнене знаходження сайту на верхніх позиціях пошукової видачі для широкого спектра запитів.
Пошукові запити формують люди – потенційні відвідувачі сайту виходячи зі своїх цілей. Наздогнати математичних методів статистичного аналізу, закладених в алгоритм роботи роботів-пошуковиків важко, тим більше, що вони безперервно уточнюються, удосконалюються, а значить змінюються.
Найдієвіший спосіб охопити при формуванні початкового ядра сайту максимальну кількість можливих запитів – це подивитися на нього як би з позиції людини, яка робить запит у пошуку.
Пошуковик створений для того, щоб допомогти людині швидко вийти на джерело інформації, що найбільше підходить пошуковому запиту. Пошуковик орієнтований, перш за все, на швидкий спосіб звузити до кількох десятків відповідних варіантів відповідей під ключову фразу (слово) запиту.
При формуванні списку цих ключових слів, які будуть основою семантики сайту, фактично визначається коло потенційних відвідувачів.

 Логічна схема підбору семантики для сайту
Логічна схема підбору семантики для сайту Підсумовуючи все сказане вище, можна коротко сказати, що семантика сайту визначається загальною кількістю застосовуваних формулювань запитів пошукової системи та їх сумарною частотою в статистиці звернень за конкретним запитом.
Усі роботи з формування та редагування семантики можна звести до наступних:
З цієї статті ви дізналися, що таке семантичне ядро сайту і як його потрібно складати.

Біологічно активна добавка на основі екстракту, отриманого з жука шпанкою мушки (або шпанки...)

Катерина МірімановаСистема мінус 60. РеволюціяСистема мінус 60 з Катериною Мірімановою «Система мінус 60. Революція»...
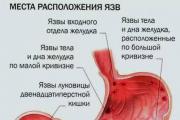
Тяжкість і здуття є причинами як звичайного переїдання, так і більш серйозних проблем із травним трактом.

Друга група крові резус-негативний з'явилася вже дуже багато років тому, коли людина перестала бути мисливцем, і...

ПСИХОЛОГІЧНІ АСПЕКТИ ФЕНОМЕНА АНОРЕКСІЇ (ЕКСПЕРИМЕНТАЛЬНЕ ДОСЛІДЖЕННЯ) Т. В. Тарасова, Є. В. Арсентьєва У...
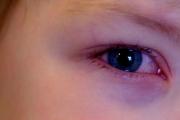
Вигляд того, що шкіра в цій області тонка, вона більш схильна до появи різного роду плям. Почервоніння під...

vseslav сб, 10/17/2015 - 20:50 Станція "Василеострівська" - входить до найстаріших станцій...

Найчастіше гриб козляк (Suillus bovinus) називається в повсякденному мовленні грибників козеням. Цей трубчастий...

Кожну людину хоч раз у житті відвідували сновидіння. Багато хто не надає їм жодного значення, але деякі...

Дедал (кратер). Діаметр: 93 км Глибина: 3 км (фото НАСА) Місяць привертав увагу людей із давніх часів. У ІІ...

У третій понеділок лютого у США відзначається Президентський день. До 70-х років святкування були присвячені...

Свого улюбленого завуча в день останнього дзвінка я хочу сказати лише одне слово: «Дякую». Але як багато це...

Кавун вважається ласою і корисною ягодою, особливо корисне його насіння. Маленькі, темно-коричневі або...

«Розвиток мови дітей 6 років» Дитина не народжується з мовою, що склалася. Не можна однозначно відповісти на запитання про...

Хоча ожиріння саме по собі не є специфічним захворюванням, але стає живильним середовищем для...

Петрушка є рослиною зеленого кольору з пряним і насиченим ароматом. Найпоширенішим...